
Outomatiese spraakherkenning (ASR) het 'n lang pad gevorder. Alhoewel dit lank gelede uitgevind is, is dit amper nooit deur enigiemand gebruik nie. Tyd en tegnologie het egter nou aansienlik verander. Oudiotranskripsie het aansienlik ontwikkel.
Tegnologieë soos KI (kunsmatige intelligensie) het die proses van oudio-na-teks-vertaling aangedryf vir vinnige en akkurate resultate. As gevolg hiervan het die toepassings daarvan in die regte wêreld ook toegeneem, met 'n paar gewilde toepassings soos Tik Tok, Spotify en Zoom wat die proses in hul mobiele toepassings ingebed het.
Laat ons dus ASR verken en ontdek hoekom dit een van die gewildste tegnologieë in 2022 is.
Wat is spraak tot teks?
Spraak na teks is 'n KI-verbeterde tegnologie wat menslike spraak van 'n analoog na 'n digitale vorm vertaal. Verder word die digitale vorm van die versamelde data in 'n teksformaat getranskribeer.
Spraak na teks word dikwels verwar met stemherkenning wat heeltemal verskil van hierdie metode. In stemherkenning is die fokus op die identifisering van die stempatrone van mense, terwyl, in hierdie metode, die sisteem probeer om die woorde wat gepraat word, te identifiseer.
Algemene name van spraak na teks
Hierdie gevorderde spraakherkenningstegnologie is ook gewild en word met die name verwys:
- Outomatiese spraakherkenning (ASR)
- Spraakherkenning
- Rekenaar spraakherkenning
- Oudio-transkripsie
- Skermlees
Begrip van die werking van outomatiese spraakherkenning
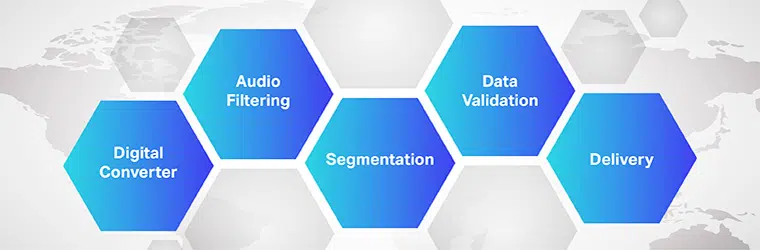
Die werking van oudio-na-teks vertalingsagteware is kompleks en behels die implementering van verskeie stappe. Soos ons weet, is spraak-na-teks 'n eksklusiewe sagteware wat ontwerp is om oudiolêers in 'n bewerkbare teksformaat om te skakel; dit doen dit deur stemherkenning te benut.
proses
- Aanvanklik, met behulp van 'n analoog-na-digitaal-omskakelaar, pas 'n rekenaarprogram linguistiese algoritmes toe op die verskafde data om vibrasies van ouditiewe seine te onderskei.
- Vervolgens word die relevante klanke gefiltreer deur die klankgolwe te meet.
- Verder word die klanke in honderdstes of duisendstes van sekondes versprei/gesegmenteer en teen foneme aangepas ('n Meetbare klankeenheid om een woord van 'n ander te onderskei).
- Die foneme word verder deur 'n wiskundige model gevoer om die bestaande data met bekende woorde, sinne en frases te vergelyk.
- Die uitvoer is in 'n teks- of rekenaargebaseerde oudiolêer.
[Lees ook: 'n Omvattende oorsig van outomatiese spraakherkenning]

Wat is die gebruike van spraak na teks?
Daar is verskeie outomatiese spraakherkenning sagteware gebruike, soos
- Inhoudsoektog: Die meeste van ons het verskuif van die tik van letters op ons fone na die druk van 'n knoppie vir die sagteware om ons stem te herken en die gewenste resultate te verskaf.
- Customer Service: Chatbots en KI-assistente wat die kliënte deur die paar aanvanklike stappe van die proses kan lei, het algemeen geword.
- Intydse geslote onderskrifte: Met verhoogde wêreldwye toegang tot inhoud het geslote onderskrifte in reële tyd 'n prominente en beduidende mark geword, wat ASR vorentoe stoot vir die gebruik daarvan.
- Elektroniese dokumentasie: Verskeie administrasiedepartemente het ASR begin gebruik om dokumentasiedoeleindes te vervul, wat voorsiening maak vir beter spoed en doeltreffendheid.
Wat is die sleuteluitdagings vir spraakherkenning?
Oudio-aantekening het nog nie die toppunt van sy ontwikkeling bereik nie. Daar is nog baie uitdagings wat die ingenieurs probeer teëwerk om die stelsel doeltreffend te maak, soos bv
- Verkry beheer oor aksente en dialekte.
- Verstaan die konteks van die gesproke sinne.
- Skeiding van agtergrondgeluide om die invoerkwaliteit te versterk.
- Skakel die kode oor na verskillende tale vir doeltreffende verwerking.
- Ontleed die visuele leidrade wat in die toespraak gebruik word in die geval van videolêers.
Oudiotranskripsies en spraak-na-teks KI-ontwikkeling
Die grootste uitdaging met outomatiese spraakherkenningsagteware is om sy uitset 100% akkuraat te skep. Aangesien die rou data dinamies is en 'n enkele algoritme nie toegepas kan word nie, word die data geannoteer om die KI op te lei om dit in die regte konteks te verstaan.
Om hierdie proses uit te voer, moet spesifieke take geïmplementeer word, soos:
 Benoemde entiteitserkenning (NER): NER is die proses om verskillende benoemde entiteite in spesifieke kategorieë te identifiseer en te segmenteer.
Benoemde entiteitserkenning (NER): NER is die proses om verskillende benoemde entiteite in spesifieke kategorieë te identifiseer en te segmenteer.- Sentiment- en onderwerpontleding: Die sagteware wat veelvuldige algoritmes gebruik, voer die sentimentontleding van die verskafde data uit om foutvrye resultate te verskaf.
 Benoemde entiteitserkenning (NER):
Benoemde entiteitserkenning (NER): - Voorneme- en gesprekontleding: Intensie-opsporing het ten doel om die KI op te lei om die spreker se bedoeling te herken. Dit word hoofsaaklik gebruik vir die skep van KI-aangedrewe chatbots.
Gevolgtrekking
Spraak-tot-teks-tegnologie is op die oomblik in 'n goeie stadium. Met meer digitale toestelle wat stemsoek- en beheerassistente in hul toepassings insluit, sal die vraag na oudiotranskripsie toeneem. As jy gretig is om hierdie indrukwekkende kenmerk by jou toepassing te voeg, kontak Shaip se spraakdata-insamelingskundiges om die volledige besonderhede te weet.


