
Kunsmatige intelligensie bevorder mensagtige interaksies met rekenaarstelsels, terwyl masjienleer hierdie masjiene toelaat om deur elke interaksie te leer om menslike intelligensie na te boots. Maar wat dryf hierdie hoogs gevorderde ML- en AI-gereedskap aan? Data-aantekening.
Data is die grondstof wat ML-algoritmes aandryf – hoe meer data jy gebruik, hoe beter sal die KI-produk wees. Alhoewel dit uiters belangrik is om toegang tot groot hoeveelhede data te hê, is dit ewe belangrik om te verseker dat hulle akkuraat geannoteer is om haalbare resultate te lewer. Data-annotasie is die datakragbron agter gevorderde, betroubare en akkurate ML-algoritmiese werkverrigting.
Rol van data-aantekening in KI-opleiding
Data-aantekening speel 'n sleutelrol in ML-opleiding en die algehele sukses van KI-projekte. Dit help om spesifieke beelde, data, doelwitte en video's te identifiseer en etiketteer dit om dit vir die masjien makliker te maak om patrone te identifiseer en data te klassifiseer. Dit is 'n mensgeleide taak wat die ML-model oplei om akkurate voorspellings te maak.
As die data-aantekening nie akkuraat uitgevoer word nie, kan die ML-algoritme nie eienskappe maklik met voorwerpe assosieer nie.
Belangrikheid van geannoteerde opleidingsdata vir KI-stelsels
Data-annotasie maak die akkurate funksionering van ML-modelle moontlik. Daar is 'n onbetwisbare verband tussen die akkuraatheid en akkuraatheid van data-aantekening en die sukses van die KI-projek.
Die wêreldwye KI-markwaarde, wat na raming $119 miljard in 2022 sal wees, sal na verwagting bereik $ 1,597 miljard deur 2030, groei teen 'n CAGR van 38% gedurende die tydperk. Terwyl die hele KI-projek deur verskeie kritieke stappe gaan, is die data-aantekeningstadium waar jou projek op die belangrikste stadium is.
Om data ter wille van data in te samel, gaan nie jou projek veel help nie. Jy het massiewe hoeveelhede relevante, hoë gehalte data nodig om jou KI-projek suksesvol te implementeer. Ongeveer 80% van jou tyd in ML-projekontwikkeling word bestee aan dataverwante take, soos etikettering, skrop, samevoeging, identifisering, aanvulling en annotering.
Data-annotasie is een gebied waar mense 'n voordeel bo rekenaars het omdat ons die aangebore vermoë het om voorneme te ontsyfer, deur dubbelsinnigheid te waag en onsekere inligting te klassifiseer.
Waarom is data-aantekening belangrik?
Die waarde en geloofwaardigheid van jou kunsmatige intelligensie-oplossing hang grootliks af van die kwaliteit van data-invoer wat vir modelopleiding gebruik word.
'n Masjien kan nie beelde verwerk soos ons nie; hulle moet opgelei word om patrone deur opleiding te herken. Aangesien masjienleermodelle voorsiening maak vir 'n wye reeks toepassings - kritieke oplossings soos gesondheidsorg en outonome voertuie - waar enige fout in data-aantekening gevaarlike gevolge kan hê.
Data-aantekening verseker dat jou KI-oplossing tot sy volle vermoë werk. Om 'n ML-model op te lei om sy omgewing akkuraat te interpreteer deur patrone en korrelasies, voorspellings te maak en die nodige aksie te neem, vereis hoogs gekategoriseer en geannoteerde opleidingsdata. Die annotasie wys die ML-model die vereiste voorspelling deur kritieke kenmerke in die datastel te merk, te transkribeer en te benoem.
Begeleide leer
Voordat ons dieper in data-annotasie delf, laat ons data-annotasie ontrafel deur leer onder toesig en sonder toesig.
'n Subkategorie van masjienleer onder toesig van masjienleer dui op KI-modelopleiding met behulp van 'n goed-benoemde datastel. In 'n leermetode onder toesig is sommige data reeds akkuraat gemerk en geannoteer. Die ML-model, wanneer dit aan nuwe data blootgestel word, maak gebruik van die opleidingsdata om vorendag te kom met 'n akkurate voorspelling gebaseer op die benoemde data.
Die ML-model word byvoorbeeld opgelei op 'n kas vol verskillende soorte klere. Die eerste stap in opleiding sal wees om die model met verskillende soorte klere op te lei deur die eienskappe en eienskappe van elke lap item te gebruik. Na die opleiding sal die masjien aparte kledingstukke kan identifiseer deur sy vorige kennis of opleiding toe te pas. Leer onder toesig kan gekategoriseer word in klassifikasie (gebaseer op kategorie) en regressie (gebaseer op werklike waarde).
Hoe data-aantekening die werkverrigting van KI-stelsels beïnvloed
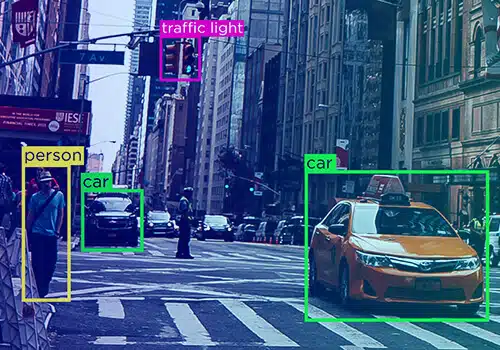 Data is nooit 'n enkele entiteit nie - dit neem verskillende vorme aan - teks, video en beeld. Nodeloos om te sê, data-aantekening kom in verskillende vorme voor.
Data is nooit 'n enkele entiteit nie - dit neem verskillende vorme aan - teks, video en beeld. Nodeloos om te sê, data-aantekening kom in verskillende vorme voor.
Vir die masjien om verskillende entiteite te verstaan en akkuraat te identifiseer, is dit belangrik om die kwaliteit van Benoemde Entiteit-etikettering te beklemtoon. Een fout met merking en annotasie, en die ML kon nie onderskei tussen Amazon nie – die e-handelswinkel, die rivier of 'n papegaai.
Boonop help data-aantekeninge masjiene om subtiele bedoelings te herken - 'n kwaliteit wat natuurlik vir mense kom. Ons kommunikeer verskillend, en mense verstaan beide eksplisiet uitgedrukte gedagtes en geïmpliseerde boodskappe. Byvoorbeeld, sosiale media-antwoorde of resensies kan beide positief en negatief wees, en die ML moet albei kan verstaan. 'Goeie plek. Sal weer besoek.' Dit is 'n positiewe frase terwyl 'Wat 'n wonderlike plek was dit vroeër nie! Ons was mal oor hierdie plek!' is negatief, en menslike annotasie kan hierdie proses baie makliker maak.

Uitdagings in data-annotasie en hoe om dit te oorkom
Twee hoofuitdagings in data-annotasie is koste en akkuraatheid.
Die behoefte aan hoogs akkurate data: Die lot van KI- en ML-projekte hang af van die kwaliteit van geannoteerde data. Die ML- en KI-modelle moet konsekwent gevoer word met goed geklassifiseerde data wat die model kan oplei om die korrelasie tussen veranderlikes te herken.
Die behoefte aan groot hoeveelhede data: Alle ML- en KI-modelle floreer op groot datastelle – 'n enkele ML-projek benodig ten minste duisende benoemde items.
Die behoefte aan hulpbronne: KI-projekte is hulpbronafhanklik, beide in terme van koste, tyd en arbeidsmag. Sonder een van hierdie, kan die kwaliteit van u data-aantekeningprojek in die wiele ry.
[Lees ook: Video-aantekening vir masjienleer ]
Beste praktyke in data-annotasie
Die waarde van data-aantekening is duidelik in die impak daarvan op die uitkoms van die KI-projek. As die datastel waarop jy jou ML-modelle oplei, deurspek is met teenstrydighede, bevooroordeeld, ongebalanseerd of korrup, kan jou KI-oplossing 'n mislukking wees. Boonop, as die etikette verkeerd is en die aantekening inkonsekwent is, sal die KI-oplossing ook onakkurate voorspellings teweegbring. So, wat is die beste praktyke in data-annotasie?
Wenke vir doeltreffende en effektiewe data-aantekening
- Maak seker dat die data-etikette wat jy skep spesifiek en in ooreenstemming met die projekbehoefte is en tog algemeen genoeg is om aan alle moontlike variasies te voldoen.
- Annoteer groot hoeveelhede data wat nodig is om die masjienleermodel op te lei. Hoe meer data jy annoteer, hoe beter is die uitkoms van die modelopleiding.
- Data-annotasieriglyne gaan 'n lang pad in die vestiging van kwaliteitstandaarde en verseker konsekwentheid regdeur die projek en oor verskeie annoteerders.
- Aangesien data-aantekeninge duur en mannekragafhanklik kan wees, maak dit sin om voorafbenoemde datastelle van diensverskaffers na te gaan.
- Om te help met akkurate data-annotasie en opleiding, bring die doeltreffendheid van mens-in-die-lus in om diversiteit te bring en kritieke gevalle te hanteer saam met die vermoëns van annotasie-sagteware.
- Prioritiseer kwaliteit deur die annoteerders te toets vir gehaltenakoming, akkuraatheid en konsekwentheid.
Belangrikheid van kwaliteitbeheer in die annotasieproses
 Gehaltedata-annotasie is die lewensbloed van hoëpresterende KI-oplossings. Goed geannoteerde datastelle help KI-stelsels om onberispelik goed te presteer, selfs in 'n chaotiese omgewing. Net so is die omgekeerde ook ewe waar. 'n Datastel deurspek met aantekeningonakkuraathede gaan teenstrydige oplossings oplewer.
Gehaltedata-annotasie is die lewensbloed van hoëpresterende KI-oplossings. Goed geannoteerde datastelle help KI-stelsels om onberispelik goed te presteer, selfs in 'n chaotiese omgewing. Net so is die omgekeerde ook ewe waar. 'n Datastel deurspek met aantekeningonakkuraathede gaan teenstrydige oplossings oplewer.
Kwaliteitsbeheer in die beeld-, video-etiketterings- en annotasieproses speel dus 'n beduidende rol in die KI-uitkoms. Die handhawing van hoëgehaltebeheerstandaarde deur die hele aantekeningproses is egter uitdagend vir klein en grootskaalse maatskappye. Die afhanklikheid van verskeie tipes annotasie-instrumente en diverse annotasie-werkmag kan moeilik wees om te assesseer en kwaliteit konsekwentheid te handhaaf.
Dit is moeilik om die kwaliteit van verspreide of afgeleë werkende data-annoteerders te handhaaf, veral vir diegene wat nie vertroud is met die vereiste standaarde nie. Boonop kan foutsporing of foutregstelling tyd neem, aangesien dit oor 'n verspreide arbeidsmag geïdentifiseer moet word.
Die oplossing sou wees om die annoteerders op te lei, 'n toesighouer te betrek, of om veelvuldige data-annoteerders te laat kyk en eweknieë nagaan vir die akkuraatheid van datastelaantekeninge. Laastens, toets gereeld die annoteerders op hul kennis van die standaarde.
Die rol van annoteerders en hoe om die regte annoteerders vir jou data te kies
Menslike annoteerders hou die sleutel tot 'n suksesvolle KI-projek. Data-annoteerders verseker dat die data akkuraat, konsekwent en betroubaar geannoteer word aangesien hulle konteks kan verskaf, bedoeling kan verstaan en die grondslag kan lê vir grondwaarhede in die data.
Sommige data word kunsmatig of outomaties geannoteer met behulp van outomatiseringsoplossings met 'n redelike mate van betroubaarheid. Jy kan byvoorbeeld honderdduisende beelde van huise van Google aflaai en dit as 'n datastel maak. Die akkuraatheid van die datastel kan egter eers betroubaar bepaal word nadat die model sy werkverrigting begin het.
Outomatiese outomatisering kan sake makliker en vinniger maak, maar onteenseglik minder akkuraat. Aan die ander kant kan 'n menslike annoteerder stadiger en duurder wees, maar hulle is meer akkuraat.
Menslike data-annoteerders kan data annoteer en klassifiseer op grond van hul vakkundigheid, aangebore kennis en spesifieke opleiding. Data-annoteerders bepaal akkuraatheid, akkuraatheid en konsekwentheid.
[Lees ook: 'n Beginnersgids vir data-aantekening: wenke en beste praktyke ]
Gevolgtrekking
Om 'n hoëpresterende KI-projek te skep, benodig u geannoteerde opleidingsdata van hoë gehalte. Alhoewel die verkryging van goed geannoteerde data konsekwent tyd kan wees en hulpbronrowend kan wees – selfs vir groot ondernemings – lê die oplossing daarin om die dienste van gevestigde data-aantekeningdiensverskaffers soos Shaip te soek. By Shaip help ons jou om jou KI-vermoëns te skaal deur ons data-aantekeningspesialisdienste deur aan die mark- en klantvraag te voldoen.


