
Kunsmatige intelligensie en groot data het die potensiaal om oplossings vir globale probleme te vind, terwyl plaaslike kwessies geprioritiseer word en die wêreld op baie diepgaande maniere transformeer. KI bring oplossings vir almal – en in alle omgewings, van huise tot werkplekke. KI rekenaars, met masjienleer opleiding, intelligente gedrag en gesprekke op 'n outomatiese dog persoonlike manier kan simuleer.
Tog het KI 'n insluitingsprobleem en is dit dikwels bevooroordeeld. Gelukkig fokus op kunsmatige intelligensie etiek kan nuwer moontlikhede inlui in terme van diversifikasie en insluiting deur onbewuste vooroordeel uit te skakel deur diverse opleidingsdata.
Belangrikheid van diversiteit in KI-opleidingsdata
 Diversiteit en kwaliteit van opleidingsdata hou verband, aangesien die een die ander beïnvloed en die uitkoms van die KI-oplossing beïnvloed. Die sukses van die KI-oplossing hang af van die diverse data dit word opgelei op. Datadiversiteit verhoed dat die KI oorpas - wat beteken dat die model slegs presteer of leer uit die data wat gebruik word om op te lei. Met oorpassing kan die KI-model nie resultate lewer wanneer dit getoets word op data wat nie in opleiding gebruik word nie.
Diversiteit en kwaliteit van opleidingsdata hou verband, aangesien die een die ander beïnvloed en die uitkoms van die KI-oplossing beïnvloed. Die sukses van die KI-oplossing hang af van die diverse data dit word opgelei op. Datadiversiteit verhoed dat die KI oorpas - wat beteken dat die model slegs presteer of leer uit die data wat gebruik word om op te lei. Met oorpassing kan die KI-model nie resultate lewer wanneer dit getoets word op data wat nie in opleiding gebruik word nie.
Die huidige stand van KI-opleiding data
Die ongelykheid of gebrek aan diversiteit in data sal lei tot onregverdige, onetiese en nie-inklusiewe KI-oplossings wat diskriminasie kan verdiep. Maar hoe en hoekom hou diversiteit in data verband met KI-oplossings?
Ongelyke voorstelling van alle klasse lei tot verkeerde identifikasie van gesigte – een belangrike voorbeeld is Google Foto's wat 'n swart paartjie as 'gorillas' geklassifiseer het. En Meta vra 'n gebruiker wat 'n video van swart mans kyk of die gebruiker wil 'aanhou om video's van primate te kyk'.
Byvoorbeeld, onakkurate of onbehoorlike klassifikasie van etniese of rasseminderhede, veral in chatbots, kan lei tot vooroordeel in KI-opleidingstelsels. Volgens die 2019-verslag oor Diskriminerende stelsels – geslag, ras, mag in KI, meer as 80% van onderwysers van KI is mans; vroulike KI-navorsers op FB maak slegs 15% en 10% op Google uit.
Die impak van uiteenlopende opleidingsdata op KI-prestasie
 Om spesifieke groepe en gemeenskappe van datavoorstelling uit te laat, kan tot skewe algoritmes lei.
Om spesifieke groepe en gemeenskappe van datavoorstelling uit te laat, kan tot skewe algoritmes lei.
Datavooroordeel word dikwels per ongeluk in die datastelsels ingebring – deur sekere rasse of groepe te ondersteek. Wanneer gesigsherkenningstelsels op verskillende gesigte opgelei word, help dit die model om spesifieke kenmerke te identifiseer, soos die posisie van gesigsorgane en kleurvariasies.
Nog 'n gevolg van 'n ongebalanseerde frekwensie van etikette is dat die stelsel 'n minderheid as 'n anomalie kan beskou wanneer dit onder druk geplaas word om 'n uitset binne 'n kort tyd te produseer.
Die bereiking van diversiteit in KI-opleidingsdata
Aan die ander kant is die generering van 'n diverse datastel ook 'n uitdaging. Die blote gebrek aan data oor sekere klasse kan tot onderverteenwoordiging lei. Dit kan versag word deur die KI-ontwikkelaarspanne meer divers te maak met betrekking tot vaardighede, etnisiteit, ras, geslag, dissipline en meer. Boonop is die ideale manier om datadiversiteitsprobleme in KI aan te spreek om dit van die begin af te konfronteer in plaas daarvan om te probeer regmaak wat gedoen is – om diversiteit in die data-insameling- en samestellingstadium in te vul.
Ongeag die hype rondom KI, dit hang steeds af van die data wat deur mense ingesamel, geselekteer en opgelei word. Die aangebore vooroordeel by mense sal weerspieël in die data wat deur hulle ingesamel word, en hierdie onbewustelike vooroordeel sluip ook in die ML-modelle in.
Stappe vir die insameling en samestelling van diverse opleidingsdata
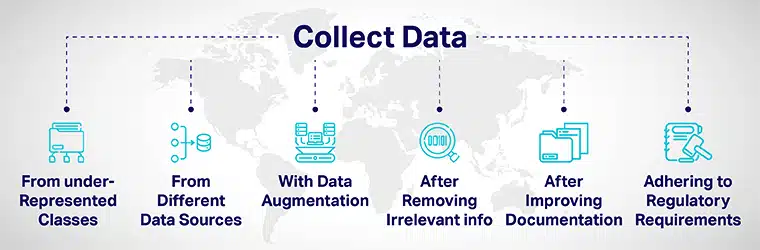
Data diversiteit kan bereik word deur:
- Voeg bedagsaam meer data van onderverteenwoordigde klasse by en stel jou modelle bloot aan uiteenlopende datapunte.
- Deur data van verskillende databronne in te samel.
- Deur datavergroting of kunsmatige manipulering van datastelle om nuwe datapunte te verhoog/in te sluit wat duidelik verskil van die oorspronklike datapunte.
- Wanneer u aansoekers vir die KI-ontwikkelingsproses aanstel, verwyder alle werk-irrelevante inligting uit die aansoek.
- Die verbetering van deursigtigheid en aanspreeklikheid deur die verbetering van dokumentasie van die ontwikkeling en evaluering van modelle.
- Bekendstelling van regulasies om diversiteit te bou en inklusiwiteit in KI stelsels vanaf die voetsoolvlak. Verskeie regerings het riglyne ontwikkel om diversiteit te verseker en KI-vooroordeel te versag wat onbillike uitkomste kan lewer.
[Lees ook: Kom meer te wete oor KI-opleidingsdata-insamelingsproses ]
Gevolgtrekking
Tans is slegs 'n paar groot tegnologiemaatskappye en leersentrums uitsluitlik betrokke by die ontwikkeling van KI-oplossings. Hierdie elite-ruimtes is deurtrek van uitsluiting, diskriminasie en vooroordeel. Dit is egter die ruimtes waar KI ontwikkel word, en die logika agter hierdie gevorderde KI-stelsels is propvol dieselfde vooroordeel, diskriminasie en uitsluiting wat deur die onderverteenwoordigde groepe gedra word.
Terwyl diversiteit en nie-diskriminasie bespreek word, is dit belangrik om die mense wat dit bevoordeel en diegene wat dit benadeel te bevraagteken. Ons moet ook kyk na wie dit benadeel – deur die idee van 'n 'normale' persoon af te dwing, kan KI moontlik 'ander' in gevaar stel.
Om diversiteit in KI-data te bespreek sonder om magsverhoudinge, billikheid en geregtigheid te erken, sal nie die groter prentjie wys nie. Om die omvang van diversiteit in KI-opleidingsdata ten volle te verstaan en hoe mense en KI saam hierdie krisis kan versag, uitreik na die ingenieurs by Shaip. Ons het diverse KI-ingenieurs wat dinamiese en diverse data vir jou KI-oplossings kan verskaf.


