
KI, groot data en masjienleer beïnvloed steeds beleidmakers, besighede, wetenskap, mediahuise en 'n verskeidenheid nywerhede regoor die wêreld. Verslae dui daarop dat die wêreldwye aannemingskoers van KI tans is 35% in 2022 – 'n yslike verhoging van 4% vanaf 2021. 'n Bykomende 42% van maatskappye ondersoek glo die vele voordele van KI vir hul besigheid.
Die krag van die vele KI-inisiatiewe en masjienleer oplossings is data. KI kan net so goed wees soos die data wat die algoritme voed. Data van lae gehalte kan lei tot lae kwaliteit uitkomste en onakkurate voorspellings.
Alhoewel daar baie aandag aan ML- en KI-oplossingsontwikkeling was, ontbreek die bewustheid van wat as 'n kwaliteitdatastel kwalifiseer. In hierdie artikel navigeer ons die tydlyn van kwaliteit AI -opleidingsdata en identifiseer die toekoms van KI deur 'n begrip van data-insameling en opleiding.
Definisie van KI-opleidingsdata
Wanneer 'n ML-oplossing gebou word, maak die hoeveelheid en die kwaliteit van die opleidingdatastel saak. Die ML-stelsel vereis nie net groot volumes dinamiese, onbevooroordeelde en waardevolle opleidingsdata nie, maar dit benodig ook baie daarvan.
Maar wat is KI-opleidingsdata?
KI-opleidingsdata is 'n versameling benoemde data wat gebruik word om die ML-algoritme op te lei om akkurate voorspellings te maak. Die ML-stelsel probeer patrone herken en identifiseer, verwantskappe tussen parameters verstaan, nodige besluite neem en evalueer op grond van die opleidingsdata.
Neem byvoorbeeld die voorbeeld van selfbestuurmotors. Die opleidingdatastel vir 'n selfbesturende ML-model moet benoemde beelde en video's van motors, voetgangers, straattekens en ander voertuie insluit.
Kortom, om die kwaliteit van die ML-algoritme te verbeter, benodig jy groot hoeveelhede goed gestruktureerde, geannoteerde en benoemde opleidingsdata.
Belangrikheid van kwaliteit opleidingsdata en die evolusie daarvan
Opleidingsdata van hoë gehalte is die sleutelinsette in KI- en ML-toepassingsontwikkeling. Data word uit verskeie bronne versamel en in 'n ongeorganiseerde vorm aangebied wat nie geskik is vir masjienleerdoeleindes nie. Gehalte-opleidingsdata - gemerk, geannoteer en gemerk - is altyd in 'n georganiseerde formaat - ideaal vir ML-opleiding.
Kwaliteit opleidingsdata maak dit makliker vir die ML-stelsel om voorwerpe te herken en dit volgens voorafbepaalde kenmerke te klassifiseer. Die datastel kan slegte modeluitkomste oplewer as die klassifikasie nie akkuraat is nie.
Die vroeë dae van KI-opleidingsdata
Ten spyte van KI wat die huidige sake- en navorsingswêreld oorheers het, het die vroeë dae voor ML oorheers Kunsmatige Intelligensie was heel anders.
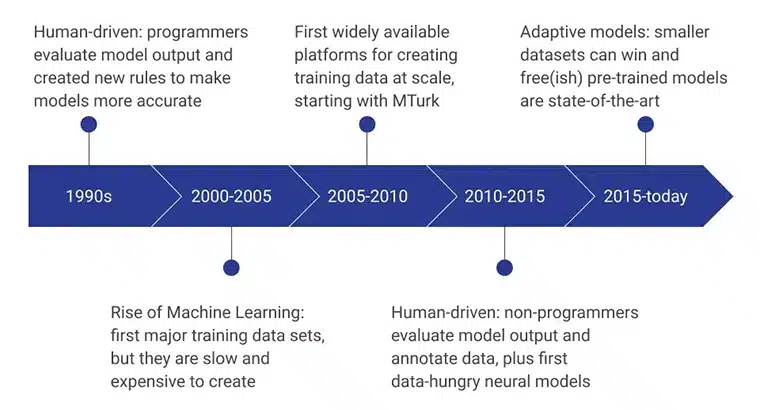
Die aanvanklike stadiums van KI-opleidingsdata is aangedryf deur menslike programmeerders wat die modeluitset geëvalueer het deur konsekwent nuwe reëls te ontwerp wat die model meer doeltreffend gemaak het. In die 2000 – 2005 tydperk is die eerste groot datastel geskep, en dit was 'n uiters stadige, hulpbron-afhanklike en duur proses. Dit het daartoe gelei dat opleidingsdatastelle op skaal ontwikkel is, en Amazon se MTurk het 'n beduidende rol gespeel in die verandering van mense se persepsies ten opsigte van data-insameling. Terselfdertyd het menslike etikettering en annotasie ook posgevat.
Die volgende paar jaar het gefokus op nie-programmeerders wat die datamodelle skep en evalueer. Tans is die fokus op vooraf-opgeleide modelle wat ontwikkel is deur gebruik te maak van gevorderde opleidingsdata-insamelingsmetodes.
Hoeveelheid bo gehalte
By die beoordeling van die integriteit van KI-opleidingdatastelle in die dag, het datawetenskaplikes gefokus op KI opleiding data hoeveelheid oor kwaliteit.
Daar was byvoorbeeld 'n algemene wanopvatting dat groot databasisse akkurate resultate lewer. Die blote volume data is glo 'n goeie aanduiding van die waarde van data. Hoeveelheid is slegs een van die primêre faktore wat die waarde van die datastel bepaal – die rol van datakwaliteit is erken.
Die bewustheid dat kwaliteit data afhang van data volledigheid, betroubaarheid, geldigheid, beskikbaarheid en tydigheid het toegeneem. Die belangrikste is dat data-geskiktheid vir die projek die kwaliteit van die data wat ingesamel is, bepaal het.
Beperkings van vroeë KI-stelsels as gevolg van swak opleidingsdata
Swak opleidingsdata, tesame met die gebrek aan gevorderde rekenaarstelsels, was een van die redes vir verskeie onvervulde beloftes van vroeë KI-stelsels.
Weens die gebrek aan kwaliteit opleidingsdata kon ML-oplossings nie visuele patrone akkuraat identifiseer wat die ontwikkeling van neurale navorsing stuit nie. Alhoewel baie navorsers die belofte van gesproke taalherkenning geïdentifiseer het, kon navorsing of ontwikkeling van spraakherkenningsinstrumente nie tot stand kom nie, danksy die gebrek aan spraakdatastelle. Nog 'n groot struikelblok vir die ontwikkeling van hoë-end KI-gereedskap was die rekenaars se gebrek aan rekenaar- en bergingsvermoëns.
Die verskuiwing na kwaliteit opleidingsdata
Daar was 'n merkbare verskuiwing in die bewustheid dat die datastel se kwaliteit saak maak. Vir die ML-stelsel om menslike intelligensie en besluitnemingsvermoëns akkuraat na te boots, moet dit floreer op hoëvolume, hoëgehalte opleidingsdata.
Dink aan jou ML-data as 'n opname - hoe groter die data monster grootte, hoe beter is die voorspelling. As die steekproefdata nie alle veranderlikes insluit nie, sal dit dalk nie patrone herken of onakkurate gevolgtrekkings bring nie.
Vooruitgang in KI-tegnologie en die behoefte aan beter opleidingsdata
 Die vooruitgang in KI-tegnologie verhoog die behoefte aan kwaliteit opleidingsdata.
Die vooruitgang in KI-tegnologie verhoog die behoefte aan kwaliteit opleidingsdata.Die begrip dat beter opleidingsdata die kans op betroubare ML-modelle verhoog, het aanleiding gegee tot beter data-insameling, annotasie en etikettering metodologieë. Die kwaliteit en relevansie van die data het die kwaliteit van die KI-model direk beïnvloed.
 Die vooruitgang in KI-tegnologie verhoog die behoefte aan kwaliteit opleidingsdata.
Die vooruitgang in KI-tegnologie verhoog die behoefte aan kwaliteit opleidingsdata.Verhoogde fokus op datakwaliteit en akkuraatheid
Vir die ML-model om akkurate uitkomste te begin verskaf, word dit gevoer op kwaliteit datastelle wat deur iteratiewe dataverfyningsstappe gaan.
Byvoorbeeld, 'n mens kan 'n spesifieke ras hond herken binne 'n paar dae nadat hy aan die ras bekendgestel is - deur prente, video's of persoonlik. Mense put uit hul ervaring en verwante inligting om hierdie kennis te onthou en op te haal wanneer nodig. Tog werk dit nie so maklik vir 'n masjien nie. Die masjien moet gevoer word met duidelik geannoteerde en benoemde beelde – honderde of duisende – van daardie spesifieke ras en ander rasse om die verbinding te maak.
'n KI-model voorspel die uitkoms deur die inligting wat opgelei is te korreleer met die inligting wat in die werklike wêreld. Die algoritme word nutteloos gemaak as die opleidingsdata nie relevante inligting insluit nie.
Belangrikheid van diverse en verteenwoordigende opleidingsdata
Verhoogde datadiversiteit verhoog ook bevoegdheid, verminder vooroordeel en bevorder billike verteenwoordiging van alle scenario's. As die KI-model opgelei word deur 'n homogene datastel te gebruik, kan jy seker wees dat die nuwe toepassing slegs vir 'n spesifieke doel sal werk en 'n spesifieke populasie sal dien.'n Datastel kan bevooroordeeld wees teenoor 'n spesifieke populasie, ras, geslag, keuse en intellektuele opinies, wat kan lei tot 'n onakkurate model.
Dit is belangrik om te verseker dat die hele data-insamelingsprosesvloei, insluitend die keuse van die onderwerppoel, samestelling, annotasie en etikettering, voldoende divers, gebalanseerd en verteenwoordigend van die populasie is.
 Verhoogde datadiversiteit verhoog ook bevoegdheid, verminder vooroordeel en bevorder billike verteenwoordiging van alle scenario's. As die KI-model opgelei word deur 'n homogene datastel te gebruik, kan jy seker wees dat die nuwe toepassing slegs vir 'n spesifieke doel sal werk en 'n spesifieke populasie sal dien.
Verhoogde datadiversiteit verhoog ook bevoegdheid, verminder vooroordeel en bevorder billike verteenwoordiging van alle scenario's. As die KI-model opgelei word deur 'n homogene datastel te gebruik, kan jy seker wees dat die nuwe toepassing slegs vir 'n spesifieke doel sal werk en 'n spesifieke populasie sal dien.Die toekoms van KI-opleidingsdata
Die toekomstige sukses van KI-modelle hang af van die kwaliteit en kwantiteit van opleidingsdata wat gebruik word om die ML-algoritmes op te lei. Dit is van kritieke belang om te erken dat hierdie verband tussen datakwaliteit en -kwantiteit taakspesifiek is en geen definitiewe antwoord het nie.
Uiteindelik word die toereikendheid van 'n opleidingsdatastel gedefinieer deur sy vermoë om betroubaar goed te presteer vir die doel wat dit gebou is.
Vooruitgang in data-insameling en annotasietegnieke
Aangesien ML sensitief is vir die gevoer data, is dit noodsaaklik om data-insameling en annotasiebeleide te stroomlyn. Foute in data-insameling, samestelling, wanvoorstelling, onvolledige metings, onakkurate inhoud, dataduplisering en foutiewe metings dra by tot onvoldoende datakwaliteit.
Outomatiese data-insameling deur data-ontginning, webskraping en data-onttrekking baan die weg vir vinniger datagenerering. Boonop dien voorafverpakte datastelle as 'n vinnige regstelling-data-insamelingstegniek.
Crowdsourcing is nog 'n baanbrekende metode van data-insameling. Alhoewel die waarheid van die data nie verseker kan word nie, is dit 'n uitstekende hulpmiddel om openbare beeld te versamel. Ten slotte, gespesialiseerde data-insameling kundiges verskaf ook data wat vir spesifieke doeleindes verkry is.
Verhoogde klem op etiese oorwegings in opleidingsdata
Met die vinnige vooruitgang in KI, het verskeie etiese kwessies opgeduik, veral in opleidingsdata-insameling. Sommige etiese oorwegings by opleidingsdata-insameling sluit ingeligte toestemming, deursigtigheid, vooroordeel en dataprivaatheid in.Aangesien data nou alles van gesigsbeelde, vingerafdrukke, stemopnames en ander kritieke biometriese data insluit, word dit krities belangrik om te verseker dat wetlike en etiese praktyke nagekom word om duur regsgedinge en skade aan reputasie te vermy.
Die potensiaal vir selfs beter kwaliteit en diverse opleidingsdata in die toekoms
Daar is 'n groot potensiaal vir hoë kwaliteit en diverse opleidingsdata in die toekoms. Danksy die bewustheid van datakwaliteit en die beskikbaarheid van dataverskaffers wat voldoen aan die kwaliteitseise van KI-oplossings.
Huidige dataverskaffers is vaardig in die gebruik van baanbrekende tegnologieë om groot hoeveelhede uiteenlopende datastelle eties en wettig te verkry. Hulle het ook interne spanne om die data wat vir verskillende ML-projekte aangepas is, te etiketteer, aan te teken en aan te bied.
 Met die vinnige vooruitgang in KI, het verskeie etiese kwessies opgeduik, veral in opleidingsdata-insameling. Sommige etiese oorwegings by opleidingsdata-insameling sluit ingeligte toestemming, deursigtigheid, vooroordeel en dataprivaatheid in.
Met die vinnige vooruitgang in KI, het verskeie etiese kwessies opgeduik, veral in opleidingsdata-insameling. Sommige etiese oorwegings by opleidingsdata-insameling sluit ingeligte toestemming, deursigtigheid, vooroordeel en dataprivaatheid in.Gevolgtrekking
Dit is belangrik om saam te werk met betroubare verskaffers met 'n skerp begrip van data en kwaliteit hoë-end KI-modelle te ontwikkel. Shaip is die voorste annotasiemaatskappy wat vaardig is in die verskaffing van pasgemaakte data-oplossings wat aan jou KI-projekbehoeftes en -doelwitte voldoen. Vennoot met ons en verken die bevoegdhede, toewyding en samewerking wat ons na die tafel bring.


