
Die internet het die deure oopgemaak vir mense wat vryelik hul menings, sienings en voorstelle oor omtrent enigiets in die wêreld op sosiale media, webwerwe en blogs. Benewens die uitspreek van hul menings, beïnvloed mense (kliënte) ook ander se koopbesluite. Die sentiment, hetsy negatief of positief, is van kritieke belang vir enige besigheid of handelsmerk wat bekommerd is oor die verkope van sy produkte of dienste.
Om besighede te help om die kommentaar te ontgin vir besigheidsgebruik is Natuurlike taal verwerking. Een uit elke vier besighede het planne om NLP-tegnologie binne die volgende jaar te implementeer om hul sakebesluite te bestuur. Deur sentimentanalise te gebruik, help NLP besighede om interpreteerbare insigte uit rou en ongestruktureerde data te verkry.
Mening ontginning of sentiment analise is 'n tegniek van NLP wat gebruik word om die presiese sentiment te identifiseer - positief, negatief of neutraal – geassosieer met kommentaar en terugvoer. Met behulp van NLP word sleutelwoorde in die kommentaar ontleed om die positiewe of negatiewe woorde in die sleutelwoord te bepaal.
Sentimente word beoordeel op 'n skaalstelsel wat sentimenttellings aan emosies in 'n teksstuk toeken (wat die teks as positief of negatief bepaal).
Wat is veeltalige sentimentanalise?

Soos die naam aandui, meertalige sentimentanalise is die tegniek om sentimenttellings vir meer as een taal uit te voer. Dit is egter nie so eenvoudig soos dit nie. Ons kultuur, taal en ervarings beïnvloed grootliks ons koopgedrag en emosies. Sonder 'n goeie begrip van die gebruiker se taal, konteks en kultuur, is dit onmoontlik om gebruikersintensies, emosies en interpretasies akkuraat te verstaan.
Alhoewel outomatisering die antwoord is op baie van ons hedendaagse probleme, masjienvertaling sagteware sal nie die nuanses van die taal, omgangstaal, subtiliteite en kulturele verwysings in die kommentaar en produk resensies dit vertaal. Die ML-nutsding kan vir jou 'n vertaling gee, maar dit is dalk nie nuttig nie. Dit is die rede waarom meertalige sentimentontleding nodig is.
Waarom is meertalige sentimentanalise nodig?
Die meeste besighede gebruik Engels as hul kommunikasiemedium, maar dit word nie deur die meeste verbruikers wêreldwyd gebruik nie.
Volgens Ethnologue praat sowat 13% van die wêreld se bevolking Engels. Daarbenewens verklaar die British Council dat ongeveer 25% van die wêreldbevolking 'n ordentlike begrip van Engels het. As hierdie syfers geglo moet word, het 'n groot deel van die verbruikers interaksie met mekaar en die besigheid in 'n ander taal as Engels.
As die hoofdoel van besighede is om hul kliëntebasis ongeskonde te hou en nuwe kliënte te lok, moet dit die menings van hul kliënte wat in hul moedertaal. Om elke opmerking handmatig te hersien of dit in Engels te vertaal is 'n omslagtige proses wat nie effektiewe resultate sal oplewer nie.
'n Volhoubare oplossing is om meertalig te ontwikkel sentiment analise stelsels wat kliënte se menings, emosies en voorstelle in sosiale media, forums, opnames en meer opspoor en ontleed.
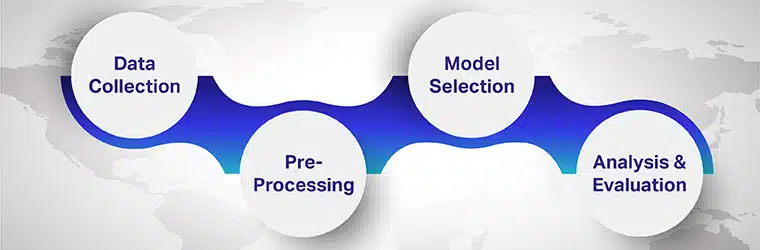
Stappe om veeltalige sentimentanalise uit te voer
Sentimentanalise, ongeag of dit in 'n enkele taal of veelvuldige tale, is 'n proses wat die toepassing van masjienleermodelle, natuurlike taalverwerking en data-ontledingstegnieke vereis om te onttrek meertalige sentimenttelling uit die data.
Die stappe betrokke by meertalige sentimentanalise is
Stap 1: Versamel data
Die insameling van data is die eerste stap in die toepassing van sentimentanalise. Om 'n veeltalige te skep sentiment analise model, is dit belangrik om data in 'n verskeidenheid tale te bekom. Alles sal afhang van die kwaliteit van data wat ingesamel, geannoteer en gemerk word. U kan data van API's, oopbronbewaarplekke en uitgewers trek.
Stap 2: Voorverwerking
Die webdata wat ingesamel word, moet skoongemaak word, en inligting daaruit verkry. Die dele van die teks wat geen spesifieke betekenis oordra nie, soos 'die' 'is' en meer, moet verwyder word. Verder moet die teks in woordgroepe gegroepeer word om gekategoriseer te word om 'n positiewe of negatiewe betekenis oor te dra.
Om die klassifikasiekwaliteit te verbeter, moet die inhoud skoongemaak word van geraas, soos HTML-etikette, advertensies en skrifte. Taal, leksikon en grammatika wat deur mense gebruik word, verskil afhangende van die sosiale netwerk. Dit is belangrik om sulke inhoud te normaliseer en voor te berei vir voorafverwerking.
Nog 'n kritieke stap in voorafverwerking is om natuurlike taalverwerking te gebruik om sinne te verdeel, stopwoorde te verwyder, spraakdele te merk, woorde in hul wortelvorm te omskep en woorde in simbole en teks te teken.
Stap 3: Modelkeuse
Reël-gebaseerde model: Die eenvoudigste metode van meertalige semantiese analise is reëlgebaseer. Die reëlgebaseerde algoritme voer die analise uit op grond van 'n stel voorafbepaalde reëls wat deur die kundiges geprogrammeer is.
Die reël kan woorde of frases spesifiseer wat positief of negatief is. As jy byvoorbeeld 'n produk- of diensresensie neem, kan dit positiewe of negatiewe woorde soos 'puik', 'stadig', 'wag' en 'nuttig' bevat. Hierdie metode maak dit maklik om woorde te klassifiseer, maar dit kan ingewikkelde of minder gereelde woorde verkeerd klassifiseer.
Outomatiese model: Die outomatiese model voer meertalige sentimentanalise uit sonder die betrokkenheid van menslike moderators. Alhoewel die masjienleermodel met menslike inspanning gebou word, kan dit outomaties werk om akkurate resultate te lewer sodra dit ontwikkel is.
Toetsdata word ontleed, en elke opmerking word met die hand as positief of negatief gemerk. Die ML-model sal dan uit die toetsdata leer deur die nuwe teks met die bestaande opmerkings te vergelyk en dit te kategoriseer.
Stap 4: Analise en Evaluering
Die reëlgebaseerde en masjienleermodelle kan met verloop van tyd en ervaring verbeter en verbeter word. 'n Leksikon van minder gereeld gebruikte woorde of lewendige tellings vir veeltalige sentimente kan opgedateer word vir vinniger en meer akkurate klassifikasie.
Die uitdaging van vertaling
Is vertaling nie genoeg nie? Eintlik nee!
Vertaling behels die oordrag van teks of groepe teks uit een taal en die vind van 'n ekwivalent in 'n ander. Vertaling is egter nie eenvoudig nóg effektief nie.
Dit is omdat mense taal gebruik nie net om hul behoeftes te kommunikeer nie, maar ook om hul emosies uit te druk. Boonop is daar groot verskille tussen verskillende tale, soos Engels, Hindi, Mandaryns en Thai. Voeg by hierdie literêre mengsel die gebruik van emosies, sleng, idiome, sarkasme en emoji's. Dit is nie moontlik om 'n akkurate vertaling van die teks te kry nie.
Sommige van die belangrikste uitdagings van masjienvertaling is
- subjektiwiteit
- Konteks
- Slang en idiome
- Sarkasme
- Vergelykings
- neutraliteit
- Emoji's en moderne gebruik van woorde.
Sonder om die beoogde betekenis van die resensies, opmerkings en kommunikasie met betrekking tot hul produkte, pryse, dienste, kenmerke en kwaliteit akkuraat te verstaan, sal besighede nie kliënte se behoeftes en menings kan verstaan nie.
Meertalige sentimentanalise is 'n uitdagende proses. Elke taal het sy unieke leksikon, sintaksis, morfologie en fonologie. Voeg hierby die kultuur, sleng, sentimente uitgespreek, sarkasme en tonaliteit, en jy het vir jouself 'n uitdagende legkaart wat 'n doeltreffende KI-aangedrewe ML-oplossing nodig het.
'n Omvattende meertalige datastel is nodig om robuuste veeltalige te ontwikkel sentiment analise gereedskap wat resensies kan verwerk en kragtige insigte aan besighede kan verskaf. Shaip is die markleier in die verskaffing van industrie-gepasmaakte, geëtiketteerde, geannoteerde datastelle in verskeie tale wat help met die ontwikkeling van doeltreffende en akkurate meertalige sentimentanalise-oplossings.


