
Data is die supermoondheid wat die digitale landskap in vandag se wêreld transformeer. Van e-posse tot sosiale media-plasings, daar is oral data. Dit is waar dat besighede nog nooit toegang tot soveel data gehad het nie, maar is toegang tot data genoeg? Die ryk bron van inligting raak nutteloos of verouderd wanneer dit nie verwerk word nie.
Ongestruktureerde teks kan 'n ryk bron van inligting wees, maar dit sal nie vir besighede nuttig wees nie, tensy die data georganiseer, gekategoriseer en ontleed word. Ongestruktureerde data, soos teks, oudio, video's en sosiale media, kom neer op 80 -90% van alle data. Boonop trek skaars 18% van organisasies na bewering voordeel uit hul organisasie se ongestruktureerde data.
Handmatig sif deur teragrepe van data wat in die bedieners gestoor is, is 'n tydrowende en eerlik onmoontlike taak. Met die vooruitgang in masjienleer, natuurlike taalverwerking en outomatisering, is dit egter moontlik om teksdata vinnig en effektief te struktureer en te ontleed. Die eerste stap in data-analise is teksklassifikasie.
Wat is teksklassifikasie?
Teksklassifikasie of -kategorisering is die proses om teks in voorafbepaalde kategorieë of klasse te groepeer. Die gebruik van hierdie masjienleerbenadering, enige teks – dokumente, weblêers, studies, regsdokumente, mediese verslae, en meer – kan geklassifiseer, georganiseer en gestruktureer word.
Teksklassifikasie is die basiese stap in natuurlike taalverwerking wat verskeie gebruike in strooiposopsporing het. Sentimentanalise, voorneme-opsporing, data-etikettering, en meer.
Moontlike gebruiksgevalle van teksklassifikasie
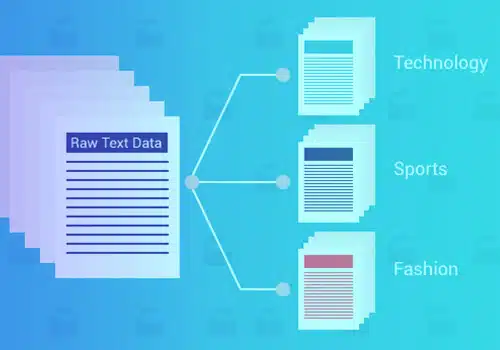 Daar is verskeie voordele verbonde aan die gebruik van masjienleer-teksklassifikasie, soos skaalbaarheid, spoed van analise, konsekwentheid en die vermoë om vinnige besluite te neem gebaseer op intydse gesprekke.
Daar is verskeie voordele verbonde aan die gebruik van masjienleer-teksklassifikasie, soos skaalbaarheid, spoed van analise, konsekwentheid en die vermoë om vinnige besluite te neem gebaseer op intydse gesprekke.
Wanneer die ML-model opgelei is op KI wat items outomaties onder voorafbepaalde kategorieë kategoriseer, kan u gemaklike blaaiers vinnig in kliënte omskakel.
Teksklassifikasieproses
Die teksklassifikasieproses begin met voorafverwerking, kenmerkkeuse, onttrekking en klassifisering van data.

Voorverwerking
Tokenisering: Teks word in kleiner en eenvoudiger teksvorme opgebreek vir maklike klassifikasie.
normalisering: Alle teks in 'n dokument moet op dieselfde vlak van begrip wees. Sommige vorme van normalisering sluit in,
- Handhawing van grammatikale of strukturele standaarde regoor die teks, soos die verwydering van wit spasies of leestekens. Of om kleinletters regdeur die teks te handhaaf.
- Verwyder voor- en agtervoegsels van woorde en bring dit terug na hul stamwoord.
- Die verwydering van stopwoorde soos 'en' 'is' 'die' en meer wat nie waarde tot die teks toevoeg nie.
Kenmerkeuse
Kenmerkkeuse is 'n fundamentele stap in teksklassifikasie. Die proses is daarop gemik om tekste met die mees relevante kenmerk voor te stel. Kenmerkkeuses help om irrelevante data te verwyder, en verbeter akkuraatheid.
Kenmerkeuse verminder die insetveranderlike in die model deur slegs die mees relevante data te gebruik en geraas uit te skakel. Op grond van die tipe oplossing wat u soek, kan u KI-modelle ontwerp word om slegs die relevante kenmerke uit die teks te kies.
Onttrekking van funksies
Kenmerkonttrekking is 'n opsionele stap wat sommige besighede onderneem om bykomende sleutelkenmerke in die data te onttrek. Kenmerkonttrekking gebruik verskeie tegnieke, soos kartering, filtering en groepering. Die primêre voordeel van die gebruik van kenmerkonttrekking is – dit help om oortollige data te verwyder en die spoed waarmee die ML-model ontwikkel word, te verbeter.
Merk data na voorafbepaalde kategorieë
Om teks na voorafbepaalde kategorieë te merk, is die laaste stap in teksklassifikasie. Dit kan op drie verskillende maniere gedoen word,
- Handmatige etikettering
- Reël-gebaseerde passing
- Leeralgoritmes – Die leeralgoritmes kan verder in twee kategorieë geklassifiseer word, soos etikettering onder toesig en etikettering sonder toesig.
- Leer onder toesig: Die ML-model kan die etikette outomaties in lyn bring met bestaande gekategoriseerde data in onder toesig gemerkte etikettering. Wanneer gekategoriseerde data reeds beskikbaar is, kan die ML-algoritmes die funksie tussen die etikette en teks karteer.
- Leer sonder toesig: Dit gebeur wanneer daar 'n gebrek aan voorheen bestaande gemerkte data is. ML-modelle gebruik groepering en reëlgebaseerde algoritmes om soortgelyke tekste te groepeer, soos gebaseer op produkaankoopgeskiedenis, resensies, persoonlike besonderhede en kaartjies. Hierdie breë groepe kan verder ontleed word om waardevolle kliëntspesifieke insigte te verkry wat gebruik kan word om pasgemaakte kliëntbenaderings te ontwerp.
Daar is veelvuldige gebruiksgevalle vir teksklassifikasie oor bedrywe heen. Alhoewel die insameling, groepering, klassifisering en onttrekking van waardevolle insigte uit teksdata nog altyd in verskeie velde gebruik is, vind teksklassifikasie sy potensiaal in bemarking, produkontwikkeling, kliëntediens, bestuur en administrasie. Dit help besighede om mededingende intelligensie, mark- en klantekennis op te doen en data-gesteunde besigheidsbesluite te neem.
Dit is nie maklik om 'n effektiewe en insiggewende teksklassifikasie-instrument te ontwikkel nie. Tog, met Shaip as jou data-vennoot, kan jy 'n effektiewe, skaalbare en koste-effektiewe KI-gebaseerde teksklassifikasie-instrument ontwikkel. Ons het tonne van akkuraat geannoteerde en gereed-vir-gebruik datastelle wat aangepas kan word vir jou model se unieke vereistes. Ons verander jou teks in 'n mededingende voordeel; kontak vandag nog.


