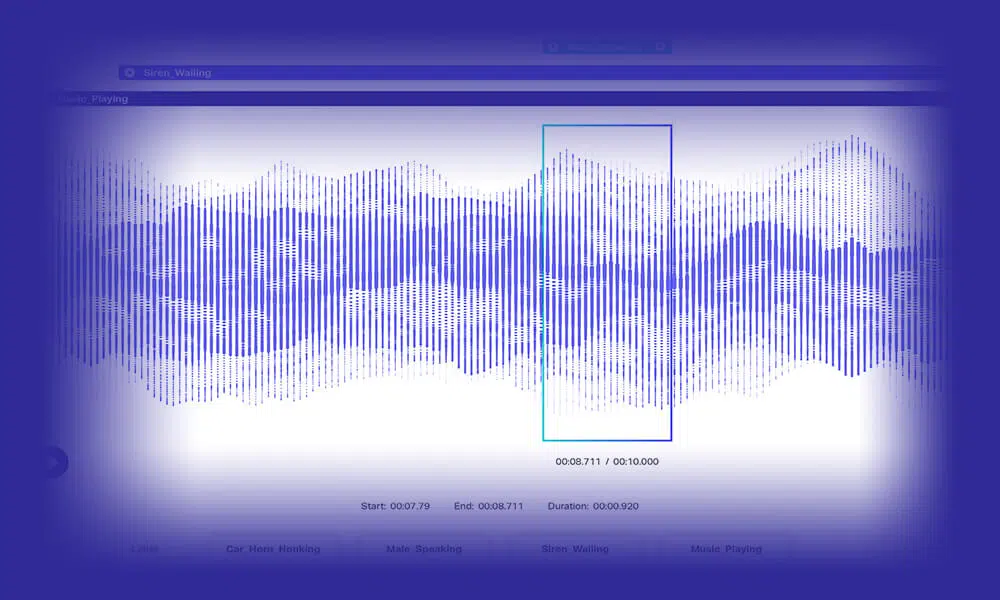


Oudio-transkripsie
Ontwikkel intelligente NLP -modelle deur vragmotors presies getranskribeerde spraak-/ klankdata in te voer. By Shaip laat ons u kies uit 'n groter reeks keuses, insluitend standaard klank, woordeliks en veeltalige transkripsie. Boonop kan u die modelle oplei met ekstra luidspreker-identifiseerders en tydstempingsdata.
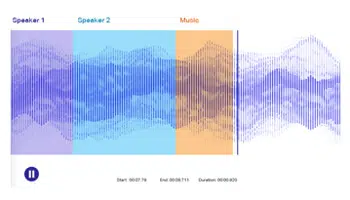
Spraaketikettering
Spraak- of klanketikettering is 'n standaard aantekeningstegniek wat handel oor die skeiding van klanke en etikettering met spesifieke metadata. Die essensie van hierdie tegniek behels die ontologiese identifisering van klanke uit 'n stuk klank en die aantekening daarvan akkuraat om die opleidingsdatastelle meer inklusief te maak

Klankindeling
Dit word deur spraakaantekeningmaatskappye gebruik om die KI's tot perfeksie op te lei, met betrekking tot die ontleding van oudio-opnames, volgens die inhoud. Met oudio-klassifikasies kan masjiene stemme en klanke identifiseer, terwyl hulle tussen die twee kan onderskei, as deel van 'n meer proaktiewe opleidingsregime.

Veeltalige klankdatadienste
Die versameling van meertalige klankdata is slegs nuttig as die aantekenaars dit kan etiketteer en segmenteer. Dit is hier waar veeltalige klankdatadienste handig te pas kom, aangesien dit betrekking het op die aantekening van spraak op grond van die diversiteit van die taal, wat deur die relevante KI's geïdentifiseer en perfek ontleed moet word.

Natuurlike taal
woord
NLU het betrekking op die aantekening van menslike spraak vir die klassifikasie van die kleinste besonderhede, soos semantiek, dialekte, konteks, spanning en meer. Hierdie vorm van geannoteerde data is sinvol om virtuele assistente en chatbots beter op te lei.
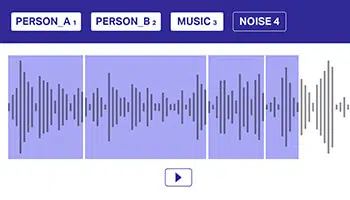
Multi-etiket
Body
Dit is belangrik om klankdata aan te meld deur gebruik te maak van verskeie etikette om modelle te help om oorvleuelende klankbronne te onderskei. In hierdie benadering kan 'n klankdatastel tot een of meer klasse behoort, wat uitdruklik aan die model oorgedra moet word vir beter besluitneming.

Luidspreker se dagboek
Dit behels die verdeling van 'n insette klanklêer in homogene segmente wat met individuele sprekers geassosieer word. Diarisering beteken om luidsprekergrense te identifiseer en die oudiolêers in segmente te groepeer om die aantal afsonderlike sprekers te bepaal. Hierdie proses help om gespreksontleding en transkripsie van oproepsentrumdialoog, mediese en regsgesprekke en vergaderings te outomatiseer.

Fonetiese transkripsie
In teenstelling met gewone transkripsie wat oudio in 'n reeks woorde omskakel, merk 'n fonetiese transkripsie op hoe woorde uitgespreek word en stel die klanke visueel voor met behulp van fonetiese simbole. Fonetiese transkripsie maak dit makliker om die verskil in uitspraak van dieselfde taal in verskeie dialekte op te let.

Mense
Toegewyde en opgeleide spanne:
- 30,000+ medewerkers vir die skep van data, etikettering en QA
- Gesertifiseerde projekbestuurspan
- Ervare produkontwikkelingspan
- Talent Pool Sourcing & Onboarding Team

proses
Die hoogste doeltreffendheid van die proses word verseker deur:
- Robuuste 6 Sigma Stage-Gate-proses
- 'N Toegewyde span van 6 Sigma swart gordels - Belangrike prosesseienaars en voldoening aan gehalte
- Deurlopende verbetering en terugvoerlus

platform
Die gepatenteerde platform bied voordele:
- Web-gebaseerde end-to-end platform
- Onberispelike kwaliteit
- Vinniger TAT
- Naadloze aflewering
Mense
Toegewyde en opgeleide spanne:
- 30,000+ medewerkers vir die skep van data, etikettering en QA
- Gesertifiseerde projekbestuurspan
- Ervare produkontwikkelingspan
- Talent Pool Sourcing & Onboarding Team
proses
Die hoogste doeltreffendheid van die proses word verseker deur:
- Robuuste 6 Sigma Stage-Gate-proses
- 'N Toegewyde span van 6 Sigma swart gordels - Belangrike prosesseienaars en voldoening aan gehalte
- Deurlopende verbetering en terugvoerlus
platform
Die gepatenteerde platform bied voordele:
- Web-gebaseerde end-to-end platform
- Onberispelike kwaliteit
- Vinniger TAT
- Naadloze aflewering

Teksaantekening
Dienste
Ons spesialiseer daarin om tekstuele data -opleiding gereed te maak deur volledige inligtingstelle aan te teken, met behulp van entiteitsaantekening, teksklassifikasie, sentimentaantekening en ander relevante instrumente.

Beeldaantekening
Dienste
Ons is trots op die etikettering van gesegmenteerde beelddatastelle om rekenaarvisiemodelle op te lei. Sommige van die relevante tegnieke sluit grensherkenning en beeldklassifikasie in.

Video-aantekening
Dienste
Shaip bied uitstekende videomerkingsdienste vir die opleiding van rekenaarvisie-modelle. Die doel is om datastelle bruikbaar te maak met instrumente soos patroonherkenning, voorwerpopsporing en meer.


