

Wat is groot taalmodelle?
Groot taalmodelle (LLM's) is gevorderde kunsmatige intelligensie (KI) stelsels wat ontwerp is om mensagtige teks te verwerk, te verstaan en te genereer. Hulle is gebaseer op diep leertegnieke en opgelei op massiewe datastelle, wat gewoonlik miljarde woorde bevat uit uiteenlopende bronne soos webwerwe, boeke en artikels. Hierdie uitgebreide opleiding stel LLM's in staat om die nuanses van taal, grammatika, konteks en selfs sommige aspekte van algemene kennis te begryp.
Sommige gewilde LLM's, soos OpenAI se GPT-3, gebruik 'n tipe neurale netwerk wat 'n transformator genoem word, wat hulle in staat stel om komplekse taaltake met merkwaardige vaardigheid te hanteer. Hierdie modelle kan 'n wye reeks take verrig, soos:
- Beantwoord vrae
- Opsommende teks
- Vertaling van tale
- Genereer inhoud
- Selfs interaktiewe gesprekke met gebruikers betrokke
Soos LLM's voortgaan om te ontwikkel, hou hulle groot potensiaal in om verskeie toepassings oor industrieë heen te verbeter en te outomatiseer, van kliëntediens en inhoudskepping tot onderwys en navorsing. Hulle opper egter ook etiese en maatskaplike bekommernisse, soos bevooroordeelde gedrag of misbruik, wat aangespreek moet word namate tegnologie vorder.

Gewilde voorbeelde van groot taalmodelle
Hier is 'n paar prominente voorbeelde van LLM's wat wyd in verskillende industrie-vertikale gebruik word:
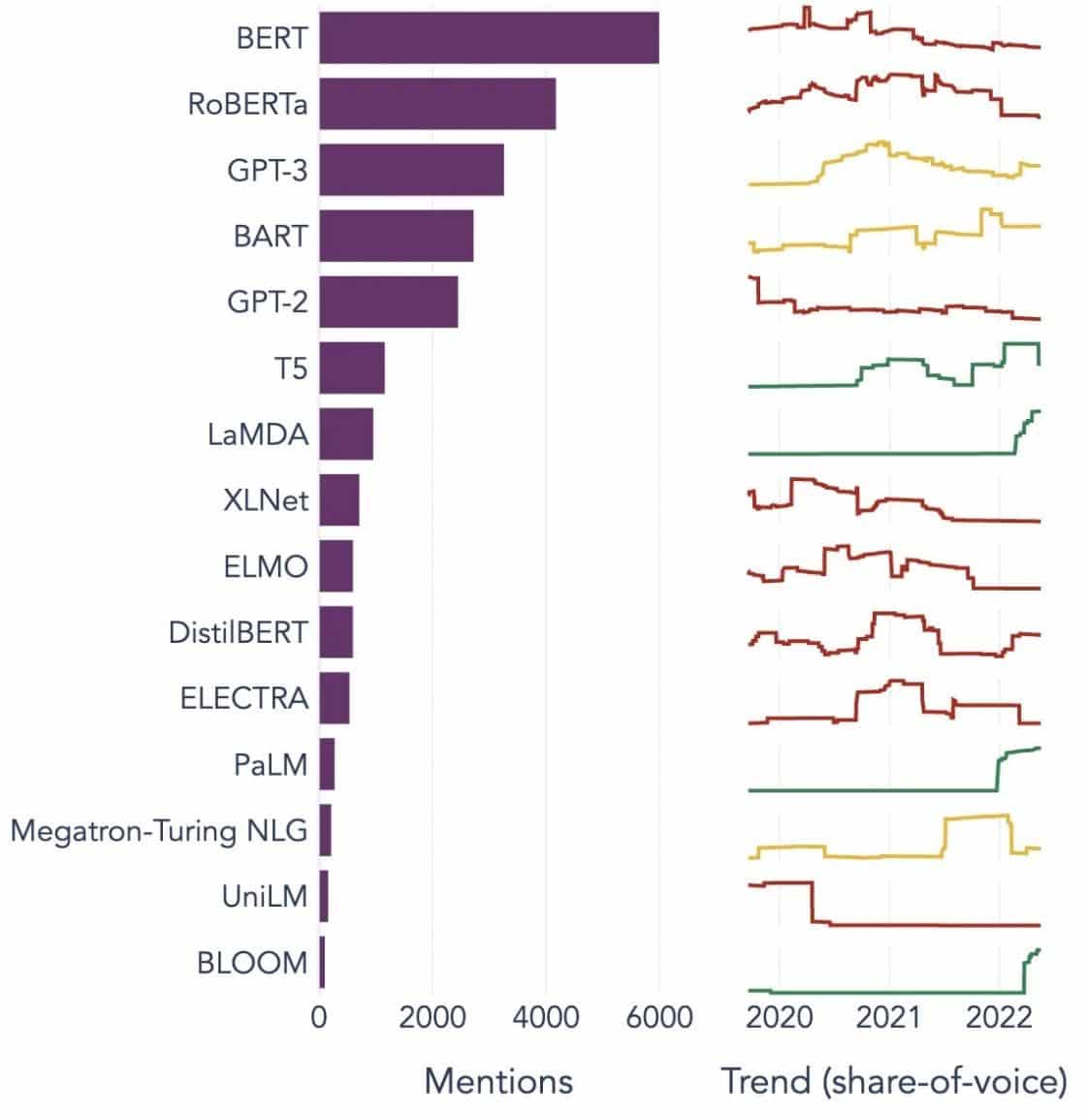
Image Bron: Op pad na datawetenskap
Hoe word LLM-modelle opgelei?
Opleiding van groot taalmodelle (LLM's) is nogal 'n prestasie wat verskeie belangrike stappe behels. Hier is 'n vereenvoudigde, stap-vir-stap oorsig van die proses:
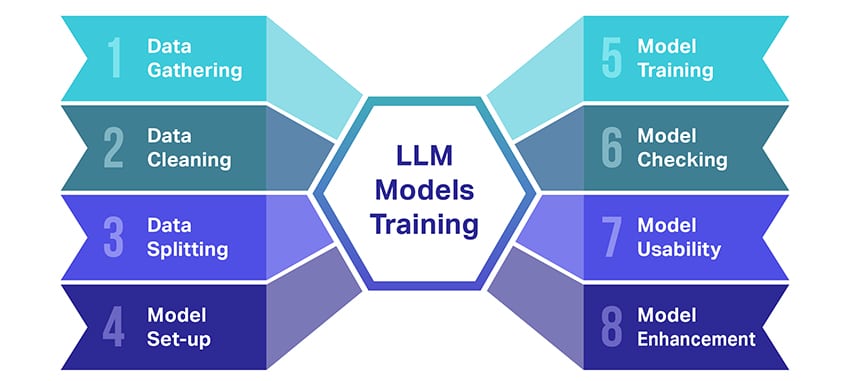
- Versamel teksdata: Opleiding van 'n LLM begin met die versameling van 'n groot hoeveelheid teksdata. Hierdie data kan van boeke, webwerwe, artikels of sosiale media-platforms kom. Die doel is om die ryk diversiteit van menslike taal vas te vang.
- Maak die data skoon: Die rou teksdata word dan opgeruim in 'n proses wat voorafverwerking genoem word. Dit sluit take in soos die verwydering van ongewenste karakters, die opbreek van die teks in kleiner dele wat tokens genoem word, en om dit alles in 'n formaat te kry waarmee die model kan werk.
- Verdeel die data: Vervolgens word die skoon data in twee stelle verdeel. Een stel, die opleidingsdata, sal gebruik word om die model op te lei. Die ander stel, die valideringsdata, sal later gebruik word om die model se werkverrigting te toets.
- Stel die model op: Die struktuur van die LLM, bekend as die argitektuur, word dan gedefinieer. Dit behels die keuse van die tipe neurale netwerk en die besluit oor verskeie parameters, soos die aantal lae en versteekte eenhede binne die netwerk.
- Opleiding van die model: Die werklike opleiding begin nou. Die LLM-model leer deur na die opleidingsdata te kyk, voorspellings te maak gebaseer op wat dit tot dusver geleer het, en dan sy interne parameters aan te pas om die verskil tussen sy voorspellings en die werklike data te verminder.
- Kontroleer die model: Die LLM-model se leer word nagegaan deur die valideringsdata te gebruik. Dit help om te sien hoe goed die model vaar en om die model se instellings aan te pas vir beter werkverrigting.
- Die gebruik van die model: Na opleiding en evaluering is die LLM-model gereed vir gebruik. Dit kan nou geïntegreer word in toepassings of stelsels waar dit teks sal genereer op grond van nuwe insette wat dit gegee word.
- Verbetering van die model: Ten slotte, daar is altyd ruimte vir verbetering. Die LLM-model kan mettertyd verder verfyn word deur opgedateerde data te gebruik of instellings aan te pas gebaseer op terugvoer en werklike gebruik.
Onthou, hierdie proses vereis aansienlike rekenaarhulpbronne, soos kragtige verwerkingseenhede en groot berging, sowel as gespesialiseerde kennis in masjienleer. Daarom word dit gewoonlik gedoen deur toegewyde navorsingsorganisasies of maatskappye met toegang tot die nodige infrastruktuur en kundigheid.
Maak die LLM staat op leer onder toesig of sonder toesig?
Groot taalmodelle word gewoonlik opgelei deur gebruik te maak van 'n metode wat toesigleer genoem word. In eenvoudige terme beteken dit dat hulle uit voorbeelde leer wat vir hulle die korrekte antwoorde wys.
 Stel jou voor dat jy 'n kind woorde leer deur vir hulle prente te wys. Jy wys vir hulle 'n prentjie van 'n kat en sê "kat", en hulle leer om daardie prentjie met die woord te assosieer. Dit is hoe leer onder toesig werk. Die model kry baie teks (die "prente") en die ooreenstemmende uitsette (die "woorde"), en dit leer om hulle te pas.
Stel jou voor dat jy 'n kind woorde leer deur vir hulle prente te wys. Jy wys vir hulle 'n prentjie van 'n kat en sê "kat", en hulle leer om daardie prentjie met die woord te assosieer. Dit is hoe leer onder toesig werk. Die model kry baie teks (die "prente") en die ooreenstemmende uitsette (die "woorde"), en dit leer om hulle te pas.
Dus, as jy 'n LLM 'n sin gee, probeer dit die volgende woord of frase voorspel op grond van wat dit uit die voorbeelde geleer het. Op hierdie manier leer dit hoe om teks te genereer wat sin maak en by die konteks pas.
Dit gesê, soms gebruik LLM's ook 'n bietjie leer sonder toesig. Dit is soos om die kind 'n kamer vol verskillende speelgoed te laat verken en op hul eie daaroor te leer. Die model kyk na ongemerkte data, leerpatrone en strukture sonder om die "regte" antwoorde te vertel.
Leer onder toesig gebruik data wat met insette en uitsette gemerk is, in teenstelling met leer sonder toesig, wat nie gemerkte uitsetdata gebruik nie.
In 'n neutedop, LLM's word hoofsaaklik opgelei deur leer onder toesig, maar hulle kan ook leer sonder toesig gebruik om hul vermoëns te verbeter, soos vir verkennende analise en dimensionaliteitvermindering.
Wat is die datavolume (in GB) wat nodig is om 'n groot taalmodel op te lei?
Die wêreld van moontlikhede vir spraakdata-herkenning en stemtoepassings is geweldig, en dit word in verskeie industrieë vir 'n oorvloed toepassings gebruik.
Die opleiding van 'n groot taalmodel is nie 'n een-grootte-pas-almal-proses nie, veral as dit kom by die data wat benodig word. Dit hang af van 'n klomp dinge:
- Die model ontwerp.
- Watter werk moet dit doen?
- Die tipe data wat jy gebruik.
- Hoe goed wil jy hê dit moet presteer?
Dit gesê, opleiding LLM's vereis gewoonlik 'n groot hoeveelheid teksdata. Maar van hoe massief praat ons? Wel, dink verder as gigagrepe (GB). Ons kyk gewoonlik na teragrepe (TB) of selfs petagrepe (PB) data.
Oorweeg GPT-3, een van die grootste LLM's in die wêreld. Dit word opgelei op 570 GB teksdata. Kleiner LLM's het dalk minder nodig – miskien 10-20 GB of selfs 1 GB gigagrepe – maar dit is steeds baie.

Maar dit gaan nie net oor die grootte van die data nie. Kwaliteit maak ook saak. Die data moet skoon en gevarieerd wees om die model effektief te help leer. En jy kan nie vergeet van ander sleutelstukke van die legkaart nie, soos die rekenaarkrag wat jy nodig het, die algoritmes wat jy vir opleiding gebruik en die hardeware-opstelling wat jy het. Al hierdie faktore speel 'n groot rol in die opleiding van 'n LLM.
Die opkoms van groot taalmodelle: waarom hulle saak maak
LLM's is nie meer net 'n konsep of 'n eksperiment nie. Hulle speel toenemend 'n kritieke rol in ons digitale landskap. Maar hoekom gebeur dit? Wat maak hierdie LLM's so belangrik? Kom ons delf na 'n paar sleutelfaktore.
Bemeestering in die nabootsing van menslike teks
LLM's het die manier waarop ons taalgebaseerde take hanteer, verander. Gebou met behulp van robuuste masjienleeralgoritmes, is hierdie modelle toegerus met die vermoë om die nuanses van menslike taal, insluitend konteks, emosie en selfs sarkasme, tot 'n mate te verstaan. Hierdie vermoë om menslike taal na te boots is nie 'n blote nuwigheid nie, dit het beduidende implikasies.
LLM's se gevorderde teksgenereringsvermoëns kan alles van inhoudskepping tot kliëntediensinteraksies verbeter.
Stel jou voor dat jy 'n komplekse vraag aan 'n digitale assistent kan vra en 'n antwoord kry wat nie net sin maak nie, maar ook samehangend, relevant is en in 'n gesprekstoon gelewer word. Dit is wat LLM's in staat stel. Dit bevorder 'n meer intuïtiewe en boeiende mens-masjien-interaksie, verryk gebruikerservarings en demokratiseer toegang tot inligting.
Bekostigbare rekenaarkrag
Die opkoms van LLM's sou nie moontlik gewees het sonder parallelle ontwikkelings in die veld van rekenaars nie. Meer spesifiek, die demokratisering van rekenaarhulpbronne het 'n beduidende rol gespeel in die evolusie en aanvaarding van LLM's.
Wolk-gebaseerde platforms bied ongekende toegang tot hoëprestasie-rekenaarhulpbronne. Op hierdie manier kan selfs kleinskaalse organisasies en onafhanklike navorsers gesofistikeerde masjienleermodelle oplei.
Boonop het verbeterings in verwerkingseenhede (soos GPU's en TPU's), gekombineer met die opkoms van verspreide rekenaars, dit haalbaar gemaak om modelle met miljarde parameters op te lei. Hierdie verhoogde toeganklikheid van rekenaarkrag maak die groei en sukses van LLM's moontlik, wat lei tot meer innovasie en toepassings in die veld.
Verandering van verbruikersvoorkeure
Verbruikers vandag wil nie net antwoorde hê nie; hulle wil innemende en verwante interaksies hê. Soos meer mense grootword met behulp van digitale tegnologie, is dit duidelik dat die behoefte aan tegnologie wat meer natuurlik en mensagtig voel, toeneem. LLM's bied 'n ongeëwenaarde geleentheid om aan hierdie verwagtinge te voldoen. Deur mensagtige teks te genereer, kan hierdie modelle innemende en dinamiese digitale ervarings skep, wat gebruikerstevredenheid en lojaliteit kan verhoog. Of dit nou KI-kletsbotte is wat kliëntediens lewer of stemassistente is wat nuusopdaterings verskaf, LLM's lui 'n era van KI in wat ons beter verstaan.
Die ongestruktureerde data goudmyn
Ongestruktureerde data, soos e-posse, sosiale media-plasings en klantresensies, is 'n skatkis van insigte. Daar word beraam dat verby 80% van ondernemingsdata is ongestruktureerd en groei teen 'n tempo van 55% per jaar. Hierdie data is 'n goudmyn vir besighede as dit behoorlik aangewend word.
LLM's kom hier ter sprake, met hul vermoë om sulke data op skaal te verwerk en sin te maak. Hulle kan take soos sentimentanalise, teksklassifikasie, inligtingonttrekking en meer hanteer, en sodoende waardevolle insigte verskaf.
Of dit nou is om tendense uit sosiale media-plasings te identifiseer of om klante-sentiment uit resensies te meet, LLM's help besighede om die groot hoeveelheid ongestruktureerde data te navigeer en datagedrewe besluite te neem.
Die groeiende NLP-mark
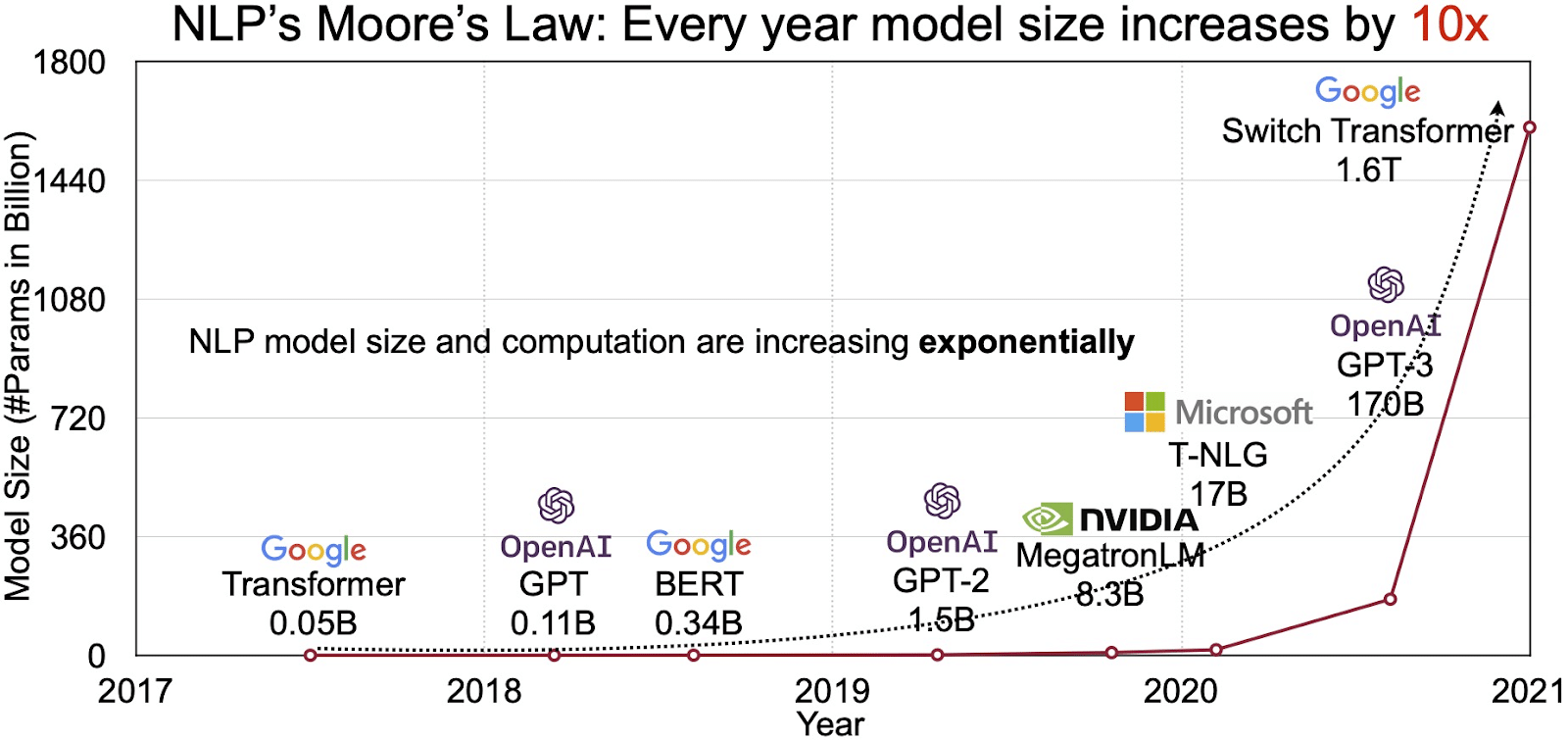
Die potensiaal van LLM's word weerspieël in die vinnig groeiende mark vir natuurlike taalverwerking (NLP). Ontleders projekteer die NLP-mark om van uit te brei $11 miljard in 2020 tot meer as $35 miljard teen 2026. Maar dit is nie net die markgrootte wat uitbrei nie. Die modelle self groei ook, beide in fisiese grootte en in die aantal parameters wat hulle hanteer. Die evolusie van LLM's oor die jare, soos gesien in die onderstaande figuur (beeldbron: skakel), onderstreep hul toenemende kompleksiteit en kapasiteit.
Gewilde gebruiksgevalle van groot taalmodelle
Hier is 'n paar van die top en mees algemene gebruiksgevalle van LLM:
- Genereer natuurlike taal teks: Groot taalmodelle (LLM's) kombineer die krag van kunsmatige intelligensie en rekenaarlinguistiek om outonoom tekste in natuurlike taal te produseer. Hulle kan in uiteenlopende gebruikersbehoeftes voorsien, soos om artikels neer te skryf, liedjies te maak of in gesprekke met gebruikers betrokke te raak.
- Vertaling deur masjiene: LLM's kan effektief aangewend word om teks tussen enige paar tale te vertaal. Hierdie modelle ontgin diepleeralgoritmes soos herhalende neurale netwerke om die linguistiese struktuur van beide bron- en teikentale te begryp en sodoende die vertaling van die bronteks in die verlangde taal te vergemaklik.
- Skep oorspronklike inhoud: LLM's het weë oopgemaak vir masjiene om samehangende en logiese inhoud te genereer. Hierdie inhoud kan gebruik word om blogplasings, artikels en ander soorte inhoud te skep. Die modelle benut hul diepgaande diep-leerervaring om die inhoud op 'n nuwe en gebruikersvriendelike manier te formateer en te struktureer.
- Ontleed sentimente: Een interessante toepassing van groottaalmodelle is sentimentanalise. Hierin word die model opgelei om emosionele toestande en sentimente wat in die geannoteerde teks voorkom, te herken en te kategoriseer. Die sagteware kan emosies soos positiwiteit, negatiwiteit, neutraliteit en ander ingewikkelde sentimente identifiseer. Dit kan waardevolle insigte verskaf oor klantterugvoer en sienings oor verskeie produkte en dienste.
- Verstaan, opsom en klassifiseer teks: LLM's vestig 'n lewensvatbare struktuur vir KI-sagteware om die teks en sy konteks te interpreteer. Deur die model opdrag te gee om groot hoeveelhede data te verstaan en te ondersoek, stel LLM's KI-modelle in staat om teks in uiteenlopende vorme en patrone te verstaan, op te som en selfs te kategoriseer.
- Vrae beantwoord: Groot taalmodelle rus Vraagbeantwoording (QA) stelsels toe met die vermoë om 'n gebruiker se natuurlike taalnavraag akkuraat waar te neem en daarop te reageer. Gewilde voorbeelde van hierdie gebruiksgeval sluit ChatGPT en BERT in, wat die konteks van 'n navraag ondersoek en deur 'n groot versameling tekste sif om relevante antwoorde op gebruikersvrae te lewer.

Gedeeltelike (POS)-etikettering
Woorde in sinne word gemerk met hul grammatikale funksie, soos werkwoorde, selfstandige naamwoorde, byvoeglike naamwoorde, ens. Hierdie proses help die model om die grammatika en die skakels tussen woorde te verstaan.

Benoemde entiteitsherkenning (NER)
Benoemde entiteite soos organisasies, liggings en mense binne 'n sin word gemerk. Hierdie oefening help die model om die semantiese betekenisse van woorde en frases te interpreteer en verskaf meer presiese response.

Sentimentanalise
Teksdata kry sentimentetikette soos positief, neutraal of negatief, wat die model help om die emosionele ondertoon van sinne te begryp. Dit is veral nuttig om te reageer op navrae wat emosies en opinies behels.
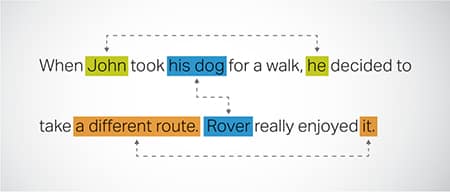
Coreference Resolusie
Identifisering en oplossing van gevalle waar na dieselfde entiteit in verskillende dele van 'n teks verwys word. Hierdie stap help die model om die konteks van die sin te verstaan, en lei dus tot samehangende response.
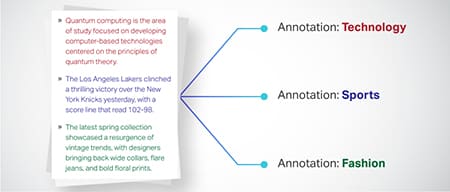
Teks Klassifikasie
Teksdata word gekategoriseer in voorafbepaalde groepe soos produkresensies of nuusartikels. Dit help die model om die genre of onderwerp van die teks te onderskei, en genereer meer pertinente response.
Shaip se offer
Shaip bied 'n wye reeks dienste om organisasies te help om hul data te bestuur, te ontleed en die meeste van hul data te maak.
Data-webskraping
Een sleuteldiens wat deur Shaip aangebied word, is dataskraping. Dit behels die onttrekking van data vanaf domeinspesifieke URL's. Deur geoutomatiseerde gereedskap en tegnieke te gebruik, kan Shaip vinnig en doeltreffend groot volumes data van verskeie webwerwe, produkhandleidings, tegniese dokumentasie, aanlynforums, aanlynresensies, kliëntediensdata, bedryfsregulerende dokumente, ens. Hierdie proses kan van onskatbare waarde wees vir besighede wanneer die insameling van relevante en spesifieke data uit 'n menigte bronne.

Masjienvertaling
Ontwikkel modelle met behulp van uitgebreide veeltalige datastelle gepaard met ooreenstemmende transkripsies vir die vertaling van teks oor verskeie tale. Hierdie proses help om linguistiese struikelblokke uit die weg te ruim en bevorder die toeganklikheid van inligting.
Taksonomie-ontginning en -skepping
Shaip kan help met taksonomie-onttrekking en skepping. Dit behels die klassifikasie en kategorisering van data in 'n gestruktureerde formaat wat die verwantskappe tussen verskillende datapunte weerspieël. Dit kan veral nuttig wees vir besighede om hul data te organiseer, wat dit meer toeganklik en makliker maak om te ontleed. Byvoorbeeld, in 'n e-handelsonderneming kan produkdata gekategoriseer word op grond van produktipe, handelsmerk, prys, ens., wat dit makliker maak vir kliënte om die produkkatalogus te navigeer.
Data-insameling
Ons data-insamelingsdienste verskaf kritiese werklike of sintetiese data wat nodig is vir die opleiding van generatiewe KI-algoritmes en die verbetering van die akkuraatheid en doeltreffendheid van u modelle. Die data is onbevooroordeeld, eties en verantwoordelik verkry, terwyl data privaatheid en sekuriteit in gedagte gehou word.

Vraag & Antwoord
Vraagantwoord (QA) is 'n subveld van natuurlike taalverwerking wat daarop gefokus is om vrae outomaties in menslike taal te beantwoord. QA-stelsels word opgelei in uitgebreide teks en kode, wat hulle in staat stel om verskeie tipes vrae te hanteer, insluitend feitelike, definisie- en opinie-gebaseerde vrae. Domeinkennis is noodsaaklik vir die ontwikkeling van QA-modelle wat aangepas is vir spesifieke velde soos kliëntediens, gesondheidsorg of voorsieningsketting. Generatiewe QA-benaderings laat modelle egter toe om teks sonder domeinkennis te genereer, wat uitsluitlik op konteks staatmaak.
Ons span spesialiste kan omvattende dokumente of handleidings noukeurig bestudeer om Vraag-Antwoord-pare te genereer, wat die skepping van Generatiewe KI vir besighede vergemaklik. Hierdie benadering kan gebruikersnavrae effektief aanpak deur relevante inligting uit 'n uitgebreide korpus te ontgin. Ons gesertifiseerde kundiges verseker die produksie van topgehalte V&A-pare wat oor uiteenlopende onderwerpe en domeine strek.

Teks Opsomming
Ons spesialiste is in staat om omvattende gesprekke of lang dialoë te distilleer, en lewer bondige en insiggewende opsommings uit uitgebreide teksdata.

Teks Generasie
Lei modelle op deur 'n breë datastel van teks in uiteenlopende style te gebruik, soos nuusartikels, fiksie en poësie. Hierdie modelle kan dan verskeie tipes inhoud genereer, insluitend nuusstukke, bloginskrywings of sosiale media-plasings, wat 'n koste-effektiewe en tydbesparende oplossing vir inhoudskepping bied.
Spraakherkenning
Ontwikkel modelle wat in staat is om gesproke taal vir verskeie toepassings te verstaan. Dit sluit stemgeaktiveerde assistente, dikteersagteware en intydse vertaalhulpmiddels in. Die proses behels die gebruik van 'n omvattende datastel wat bestaan uit oudio-opnames van gesproke taal, saam met hul ooreenstemmende transkripsies.

Produkaanbevelings
Ontwikkel modelle met behulp van uitgebreide datastelle van klante se koopgeskiedenis, insluitend etikette wat aandui watter produkte klante geneig is om te koop. Die doel is om presiese voorstelle aan kliënte te verskaf, en sodoende verkope te bevorder en kliëntetevredenheid te verbeter.
Byskrifte van foto's
Revolusioneer jou beeld interpretasie proses met ons state-of-the-art, KI-gedrewe Image Captioning diens. Ons gee lewenskrag in prente deur akkurate en kontekstueel betekenisvolle beskrywings te produseer. Dit baan die weg vir innoverende betrokkenheid en interaksie moontlikhede met jou visuele inhoud vir jou gehoor.

Opleiding van teks-na-spraak-dienste
Ons verskaf 'n uitgebreide datastel wat bestaan uit menslike spraak-oudio-opnames, ideaal vir die opleiding van KI-modelle. Hierdie modelle is in staat om natuurlike en boeiende stemme vir jou toepassings te genereer en sodoende 'n kenmerkende en meeslepende klankervaring vir jou gebruikers te lewer.



