
Robuuste opleidingsdataplatform
ShaipCloud™ gebruik gepatenteerde tegnologie om werkladings in te samel, op te spoor en te monitor, oudio en uitinge te transkribeer, teks, beeld en video aan te teken, asook om kwaliteitbeheer en data-uitruiling te bestuur. Die resultaat? Jou KI-projek kry die hoogste gehalte data moontlik. Nie net kry jy dit vinnig en teen 'n bekostigbare koste nie, maar namate jou KI-projek groei, groei ShaipCloud™ daarmee deur skaalbaarheid en platformintegrasies wat nodig is om jou werk makliker te maak en suksesvolle resultate te lewer.

Die platform vereenvoudig werkvloei, verminder die wrywing om met 'n verspreide globale arbeidsmag te werk, bied groter sigbaarheid en intydse kwaliteitbeheer. Daar is dataplatforms. Dan is daar KI-dataplatforms. Ons is laasgenoemde omdat die veilige ShaipCloud™ mens-in-die-lus-platform die ongeëwenaarde funksionaliteit en spoed bied om groot hoeveelhede data (teks, oudio, beelde en video) te versamel, te transformeer en te annoteer om KI op te lei en te verbeter. ML-algoritmes vir NLP en Computer Vision gebruik gevalle.





Beeldversameling
Skep data wat aangepas is vir enige domein en gebruiksgeval deur ons uitgebreide netwerk van wêreldwye vakkundiges. Ons bied uiteenlopende beelddatastelle uit verskeie streke. Gebruik ons KI-gemeenskap om toegang te verkry tot duisende beelde wat van lande regoor die wêreld verkry is.

Beeldaantekening
Ons bied 'n uitgebreide keuse van annotasiestyle, wat 2D- en 3D-begrenskassies, veelhoekaantekeninge, landmerk-identifikasie en semantiese segmentering insluit.

Video versameling
Verkry of vervaardig videodata wat aangepas is vir enige domein en gebruiksgeval deur ons uitgebreide netwerk van wêreldwye vakkundiges. Ons bied diverse, akteur-gebaseerde video-scenario's in verskeie tale om jou projekte te ondersteun, wat 'n wye verskeidenheid situasies dek.

Video-aantekening
Annoteer video's doeltreffend en akkuraat raam-vir-raam met tydstempels. Gebruik ons video-transkripsiedienste om oudio in teks te omskep, wat soekvermoë en toeganklikheid vir SEO-doeleindes verbeter.

Versameling van spraakdata
Versamel topgehalte, diverse data in meer as 150 tale en dialekte, wat 'n wye verskeidenheid van demografie insluit, soos geslag en ouderdom. Ons data dek verskeie spreker-eienskappe, dialoogtipes—insluitend monoloë, dubbelspreker- en veelsprekergesprekke, sowel as geskrewe en spontane toespraak. Ons verskaf ook data van 'n verskeidenheid omgewings, soos huise, restaurante, oproepsentrums, voertuie en ateljee-opnames, wat 'n uitgebreide reeks scenario's dek.
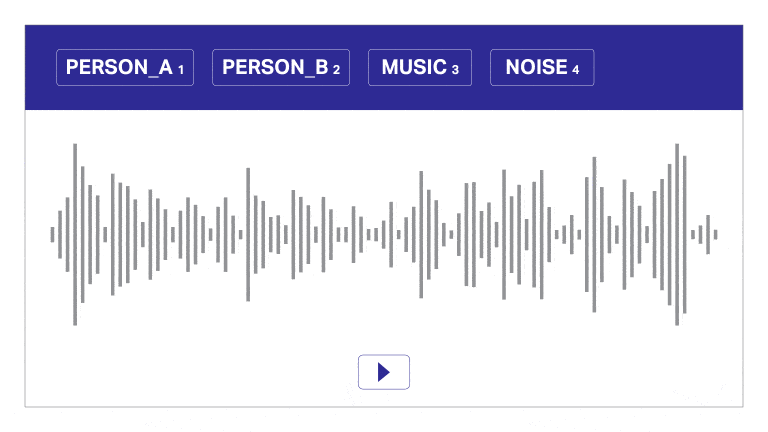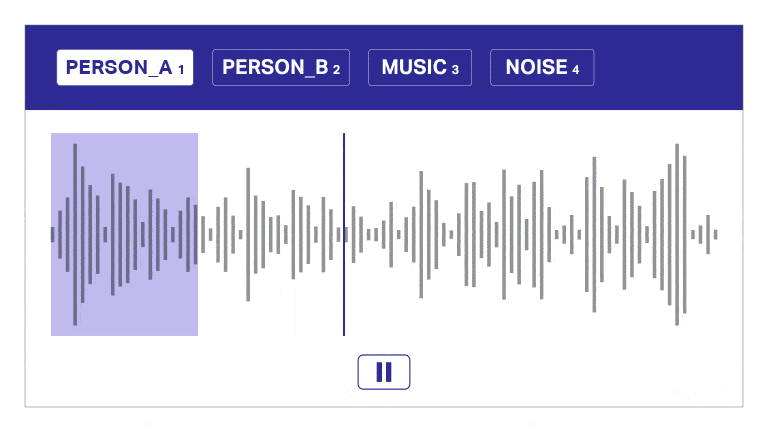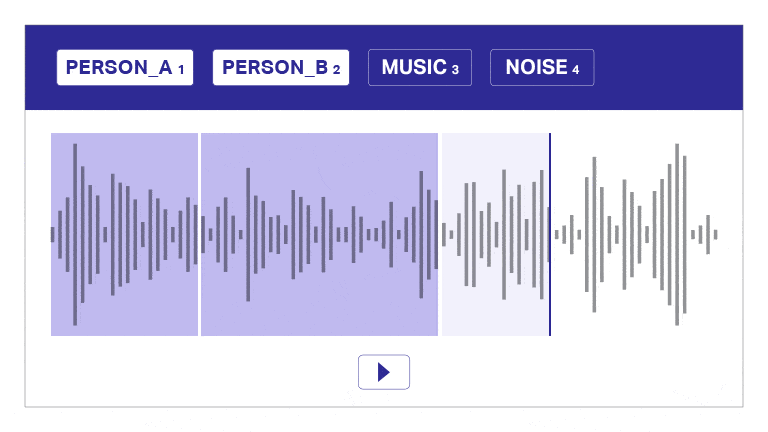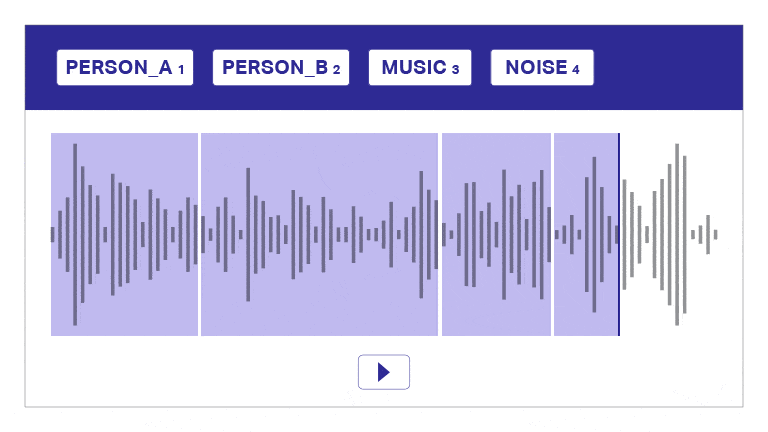
Spraakdata-aantekening
Ons annotasie- en transkripsienutsding segmenteer oudio outomaties in lae, onderskei tussen luidsprekers en verskaf tydstempels vir doeltreffende oudio-aantekeninge. Hierdie gebruikersvriendelike hulpmiddel maak vinnige en presiese transkripsie en tydstempel moontlik, wat akkurate aantekeninge op skaal moontlik maak.

Versameling van teksdata
Verbeter jou KI-modelle en versterk hul aanpasbaarheid deur gebruik te maak van hoë gehalte, gevarieerde tekstuele en dokumentdata in 'n wye verskeidenheid tale en formate, wat wissel van kwitansies en aanlyn nuusartikels tot chatbots-voornemens en -uitsprake.

Teksdata-aantekening
Ons teksaantekeningnutsgoed vereenvoudig die proses om teks in diepte te annoteer, wat jou modelle in staat stel om teks te verstaan en waardevolle insigte te onttrek. Daarbenewens bied ons Benoemde Entiteit Onttrekking en Entiteit Koppeling dienste om jou teks analise vermoëns verder te verbeter.




