
Die sleutel tot die oorkoming van AI-ontwikkelingshindernisse: betroubaarder data
Vandag het die gemiddelde persoon nou miljoene keer meer rekenaarkrag in sy sak as wat NASA die maanlanding in 1969 moes aflê. Dieselfde alomteenwoordige toestel wat gemaklik 'n oorvloed rekenaarkrag demonstreer, vervul ook nog 'n voorvereiste vir AI se goue era: 'n oorvloed data. Volgens insigte van die Information Overload Research Group is 90% van die wêreld se data die afgelope twee jaar geskep. Noudat die eksponensiële groei in rekenaarkrag uiteindelik saamgeval het met ewe meteore groei in die generering van data, ontplof AI-innovasies so dat sommige kenners dink dat hulle 'n vierde industriële rewolusie sal begin.
Data van die National Venture Capital Association dui aan dat die AI-sektor in die eerste kwartaal van 6.9 'n rekord van 2020 miljard dollar belê het. Dit is nie moeilik om die potensiaal van AI-instrumente raak te sien nie, want daar word reeds oral om ons getap. Sommige van die meer sigbare gebruiksgevalle vir KI-produkte is die aanbevelingsmotors agter ons gunsteling toepassings soos Spotify en Netflix. Alhoewel dit lekker is om 'n nuwe kunstenaar te ontdek om na te luister of 'n nuwe TV-program om na te kyk, is hierdie implementerings redelik laag. Ander algoritmes se puntetellings - deels om te bepaal waar studente tot die universiteit toegelaat word - en nog ander deursy kandidaat-CV's en besluit watter aansoekers 'n spesifieke werk kry. Sommige KI-instrumente kan selfs lewens- of doodsimplikasies hê, soos die KI-model wat kyk vir borskanker (wat beter is as dokters).
Ondanks bestendige groei in beide werklike voorbeelde van KI-ontwikkeling en die aantal opstart wat meeding om die volgende generasie transformasie-instrumente te skep, bly uitdagings vir effektiewe ontwikkeling en implementering. In die besonder is die uitvoer van KI net so akkuraat as wat die invoer toelaat, wat beteken dat die belangrikste gehalte is.

Navigeer na komplekse nakomingsvereistes
Asof die vind van kwaliteitsdata nie moeilik genoeg was nie, is sommige van die bedrywe wat die meeste voordeel trek uit KI-datainnovasies, ook die swaarste gereguleer. Gesondheidsorg is miskien die beste voorbeeld, en hoewel 'n opname van HIT Infrastructure bevind het dat 91% van die insiders in die industrie meen dat die tegnologie toegang tot sorg kan verbeter, word optimisme getemper deur die feit dat 75% dit as 'n bedreiging vir pasiënt se veiligheid en privaatheid beskou. - en pasiënte is nie die enigste in gevaar nie.
Die omvattende regulasies wat deur die Wet op draagbaarheid en aanspreeklikheid van gesondheidsversekering uitgevaardig word, word nou gekruis met verskillende plaaslike hindernisse rakende die nakoming van data, soos die Algemene Regulering van die Beskerming van Persone in Europa, die Kaliforniese Wet op Verbruikersbeskerming in die Verenigde State en die Wet op die Beskerming van Persoonlike Data in Singapoer. Daar sal nog baie meer by hierdie plaaslike voorskrifte gevoeg word, en namate telehealth 'n belangriker bron van gesondheidsorgdata is, is dit waarskynlik dat die regulasies 'n nog strenger greep sal kry op pasiëntdata tydens vervoer. As gevolg hiervan sal Shaip se veilige en nakomende wolkplatform 'n nog meer waardevolle manier wees om data van gesondheidsorg bymekaar te maak en toegang te verkry tot die opleiding van KI-produkte.
Persoonlik identifiseerbare inligting kan 'n beduidende bedreiging vir u KI-ontwikkeling wees, maar selfs 'n volledige implementering is in gevaar as dit nie die akkurate resultate kan lewer wat slegs met verskillende opleidingsdata beskikbaar is nie. 'N 2020-studie in die Journal of the American Medical Association het getoon dat algoritmes vir masjienleer in die mediese veld meestal opgelei word met data van pasiënte in Kalifornië, New York en Massachusetts. Aangesien hierdie pasiënte minder as 'n vyfde van die Amerikaanse bevolking verteenwoordig, om niks van die res van die wêreld te sê nie, is dit moeilik om voor te stel hoe hierdie modelle allesbehalwe bevooroordeelde resultate kan lewer.

 Shaip erken die moeilikheid om inligting, wat geografies uiteenlopend is, te bekom en bied gelisensieerde gesondheidsorgdata uit 'n wye verskeidenheid streke wat spesifiek saamgestel is met die doel om akkurate algoritmes op te stel. Hierdie data kom in die vorm van teks, soos mediese rekords of inligting oor eise, mediese diagnostiese beelding, soos CT-skanderings, klank soos gesproke aantekeninge van dokters of gesprekke tussen dokters en pasiënte, en selfs video uit MRI-resultate. Dit word ook heeltemal geïdentifiseer en geanonimiseer, wat u organisasie beskerm teen die etiese en finansiële implikasies wat kan lei tot 'n oortreding van die toenemende aantal regulasies wat geld vir sowel plaaslike as internasionale oorsprong.
Shaip erken die moeilikheid om inligting, wat geografies uiteenlopend is, te bekom en bied gelisensieerde gesondheidsorgdata uit 'n wye verskeidenheid streke wat spesifiek saamgestel is met die doel om akkurate algoritmes op te stel. Hierdie data kom in die vorm van teks, soos mediese rekords of inligting oor eise, mediese diagnostiese beelding, soos CT-skanderings, klank soos gesproke aantekeninge van dokters of gesprekke tussen dokters en pasiënte, en selfs video uit MRI-resultate. Dit word ook heeltemal geïdentifiseer en geanonimiseer, wat u organisasie beskerm teen die etiese en finansiële implikasies wat kan lei tot 'n oortreding van die toenemende aantal regulasies wat geld vir sowel plaaslike as internasionale oorsprong.
Oorkom van AI-ontwikkelingshindernisse
AI-ontwikkelingspogings sluit belangrike hindernisse in, ongeag in watter bedryf dit plaasvind, en die proses om van 'n haalbare idee na 'n suksesvolle produk te kom, is moeilik. Tussen die uitdagings van die verkryging van die regte data en die noodsaaklikheid om dit te anonimiseer om aan alle relevante regulasies te voldoen, kan dit voel asof dit maklik is om 'n algoritme te konstrueer en op te lei.
Om u organisasie alle voordele te gee wat nodig is in die poging om 'n baanbrekende nuwe AI-ontwikkeling te ontwerp, moet u dit oorweeg om saam te werk met 'n maatskappy soos Shaip. Chetan Parikh en Vatsal Ghiya het Shaip gestig om maatskappye te help om die oplossings te ontwikkel wat gesondheidsorg in die VSA kan transformeer. Na meer as 16 jaar in ons besigheid, het ons maatskappy gegroei tot meer as 600 spanlede, en ons het saam met honderde klante om oortuigende idees in KI-oplossings te omskep.
Met ons mense, prosesse en platform wat vir u organisasie werk, kan u die volgende vier voordele onmiddellik ontsluit en u projek katapulteer om suksesvol te voltooi:
1. Die vermoë om u datawetenskaplikes te bevry
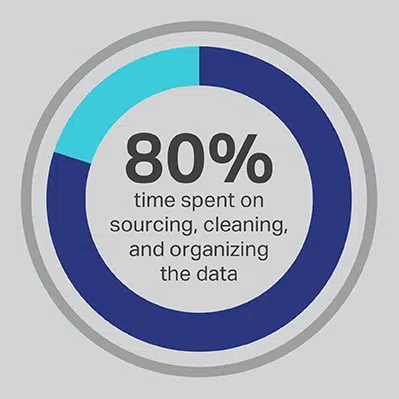
Daar is geen oplossing nie, die AI -ontwikkelingsproses verg baie tyd, maar u kan altyd die funksies optimaliseer wat u span die meeste tyd bestee. U het u data -wetenskaplikes aangestel omdat hulle kundiges is in die ontwikkeling van gevorderde algoritmes en masjienleermodelle, maar die navorsing toon deurgaans aan dat hierdie werkers eintlik 80% van hul tyd bestee aan die verkryging, skoonmaak en organisering van die data wat die projek sal dryf. Meer as driekwart (76%) van data-wetenskaplikes meld dat hierdie alledaagse data-insamelingsprosesse ook hul minste gunsteling dele van die werk is, maar die behoefte aan kwaliteitsdata laat slegs 20% van hul tyd oor vir die werklike ontwikkeling, die interessantste en intellektueel stimulerende werk vir baie data -wetenskaplikes. Deur data deur middel van 'n derdeparty-verkoper soos Shaip te verkry, kan 'n onderneming sy duur en talentvolle data-ingenieurs toelaat om hul werk as data-oppassers uit te kontrakteer en eerder hul tyd te bestee aan die dele van AI-oplossings waar hulle die meeste waarde kan lewer.
2. Die vermoë om beter uitkomste te bereik
 Baie AI-ontwikkelingsleiers besluit om oopbron- of skaargegewensdata te gebruik om uitgawes te verminder, maar op die langtermyn kos dit byna altyd meer. Hierdie tipe data is maklik beskikbaar, maar dit kan nie ooreenstem met die kwaliteit van versigtig saamgestelde datastelle nie. Veral data wat oorvloedig is, bevat baie foute, weglatings en onakkuraathede, en hoewel hierdie probleme soms onder die wakende oë van u ingenieurs tydens die ontwikkelingsproses uitgesorteer kan word, verg dit aanvullende herhalings wat nie nodig sou wees as u met 'n hoër -kwaliteit data van die begin af.
Baie AI-ontwikkelingsleiers besluit om oopbron- of skaargegewensdata te gebruik om uitgawes te verminder, maar op die langtermyn kos dit byna altyd meer. Hierdie tipe data is maklik beskikbaar, maar dit kan nie ooreenstem met die kwaliteit van versigtig saamgestelde datastelle nie. Veral data wat oorvloedig is, bevat baie foute, weglatings en onakkuraathede, en hoewel hierdie probleme soms onder die wakende oë van u ingenieurs tydens die ontwikkelingsproses uitgesorteer kan word, verg dit aanvullende herhalings wat nie nodig sou wees as u met 'n hoër -kwaliteit data van die begin af.
Vertrou op open source-data is nog 'n algemene kortpad met sy eie stel slaggate. 'N Gebrek aan differensiasie is een van die grootste probleme, want 'n algoritme wat opgelei word met behulp van open source data, word makliker herhaal as een wat op gelisensieerde datastelle gebou is. Deur hierdie roete te volg, nooi u kompetisie uit van ander deelnemers in die ruimte wat u pryse kan onderdruk en te eniger tyd markaandeel kan neem. As u op Shaip vertrou, verkry u toegang tot die hoogste gehalte data wat deur 'n bekwame bestuurde personeel saamgestel word, en ons kan u 'n eksklusiewe lisensie verleen vir 'n persoonlike datastel wat verhoed dat mededingers u hardverwante intellektuele eiendom maklik kan herskep.
3. Toegang tot ervare professionele persone
 Al bevat u interne rooster vaardige ingenieurs en talentvolle data-wetenskaplikes, kan u AI-instrumente baat vind by die wysheid wat net deur ervaring kom. Ons vakdeskundiges het aanleiding gegee tot talle KI-implementasies in hul vakgebiede en onderweg waardevolle lesse geleer, en hul enigste doel is om u te help om joune te bereik.
Al bevat u interne rooster vaardige ingenieurs en talentvolle data-wetenskaplikes, kan u AI-instrumente baat vind by die wysheid wat net deur ervaring kom. Ons vakdeskundiges het aanleiding gegee tot talle KI-implementasies in hul vakgebiede en onderweg waardevolle lesse geleer, en hul enigste doel is om u te help om joune te bereik.
Met domeinkenners wat data vir u identifiseer, organiseer, kategoriseer en etiketteer, weet u dat die inligting wat gebruik word om u algoritme op te lei, die beste moontlike resultate kan lewer. Ons doen ook gereeld gehalteversekering om seker te maak dat data aan die hoogste standaarde voldoen en nie net in 'n laboratorium nie, maar ook in 'n werklike situasie sal optree.
4. 'n Versnelde ontwikkelingstydlyn
KI-ontwikkeling vind nie oornag plaas nie, maar dit kan vinniger gebeur as u met Shaip saamwerk. Interne data-insameling en -aantekeninge skep 'n beduidende bedrywige knelpunt wat die res van die ontwikkelingsproses hou. Om met Shaip te werk, gee u onmiddellike toegang tot ons uitgebreide biblioteek met gereed-vir-gebruik-data, en ons kundiges kan met behulp van ons diep industrie-kennis en wêreldwye netwerk enige soort addisionele insette verkry wat u benodig. Sonder die las van aankope en annotasies, kan u span dadelik aan die werklike ontwikkeling werk, en ons opleidingsmodel kan help om vroeë onakkuraathede te identifiseer om die nodige herhalings om akkuraatheidsdoelwitte te bereik, te verminder.
As u nie gereed is om alle aspekte van u databestuur uit te kontrakteer nie, bied Shaip ook 'n wolkgebaseerde platform wat spanne help om verskillende soorte data doeltreffender te vervaardig, te verander en aan te teken, insluitend ondersteuning vir beelde, video, teks en klank. . ShaipCloud bevat 'n verskeidenheid intuïtiewe instrumente vir validering en werkvloei, soos 'n gepatenteerde oplossing om werklading op te spoor en te monitor, 'n transkripsie-instrument om komplekse en moeilike klankopnames te transkribeer, en 'n komponent vir kwaliteitskontrole om kompromislose gehalte te verseker. Die beste van alles is dat dit skaalbaar is, sodat dit kan groei namate die verskillende eise van u projek toeneem.
Die ouderdom van KI-innovasie begin nou eers, en ons sal ongelooflike vooruitgang en innovasies sien in die komende jare wat die potensiaal het om hele bedrywe te hervorm of selfs die samelewing as geheel te verander. By Shaip wil ons ons kundigheid gebruik om as transformerende krag te dien, wat die mees revolusionêre maatskappye in die wêreld help om die krag van KI-oplossings te benut om ambisieuse doelwitte te bereik.
Ons het diep ervaring in gesondheidsorgtoepassings en AI, maar ons het ook die nodige vaardighede om modelle op te lei vir bykans enige soort toepassing. Vir meer inligting oor hoe Shaip u kan help om u projek van idee tot implementering te neem, kyk na die vele bronne wat op ons webwerf beskikbaar is of kontak ons vandag.
