


Wat is Conversational AI
Gespreks-KI is 'n gevorderde vorm van kunsmatige intelligensie wat masjiene in staat stel om in interaktiewe, mensagtige gesprekke met gebruikers betrokke te raak. Hierdie tegnologie verstaan en interpreteer menslike taal om natuurlike gesprekke te simuleer. Dit kan mettertyd uit interaksies leer om kontekstueel te reageer.
Gespreks-KI-stelsels word wyd gebruik in toepassings soos kletsbotte, stemassistente en kliëntediensplatforms oor digitale en telekommunikasiekanale.
Die gesels-KI-mark het die afgelope jaar vinnige groei beleef. Gespreks-KI, wat aanvanklik vir vermaaklikheidsdoeleindes ontwikkel is, het 'n integrale deel van die digitale ekosisteem geword. Hier is 'n paar sleutelstatistieke om die impak daarvan te illustreer:
- Die wêreldwye gesprekke-KI-mark is in 6.8 op $2021 miljard gewaardeer en sal na verwagting teen 18.4 tot $2026 miljard groei teen 'n CAGR van 22.6%. Teen 2028 word verwag dat die markgrootte sal bereik Van $ 29.8 miljard.
- Ten spyte van die voorkoms daarvan, 63% van gebruikers is onbewus daarvan dat hulle KI in hul daaglikse lewens gebruik.
- A Gartner-opname het gevind dat baie besighede kletsbotte as hul primêre KI-toepassing geïdentifiseer het, met byna 70% van witboordjiewerkers wat na verwagting daagliks met gespreksplatforms sal kommunikeer teen 2022.
- Sedert die pandemie het die volume interaksies wat deur gespreksagente hanteer word met soveel as toegeneem 250% oor verskeie industrieë.
- Die aandeel van bemarkers wat KI vir digitale bemarking gebruik wêreldwyd het dramaties gestyg, van 29% in 2018 tot 84% in 2020.
- In 2022, 91% van volwasse stemassistent-gebruikers het gespreks-KI-tegnologie op hul slimfone gebruik.
- Blaai en soek na produkte was die top inkopie-aktiwiteite uitgevoer met behulp van stemassistent-tegnologie onder Amerikaanse gebruikers in 'n 2021-opname.
- Onder tegniese professionele mense wêreldwyd, byna 80% gebruik virtuele assistente vir kliëntediens.
- Teen 2024 glo 73% van Noord-Amerikaanse kliëntediensbesluitnemers dat aanlynklets, videoklets, chatbots of sosiale media die mees gebruikte kliëntedienskanale.
- In 'n 2021-opname, 86% van Amerikaanse bestuurders het ingestem dat KI 'n "hoofstroomtegnologie" binne hul maatskappy sou word.
- Vanaf Februarie 2022, 53% van Amerikaanse volwassenes het die afgelope jaar met 'n KI-kletsbot vir kliëntediens gekommunikeer.
- In 2022, 3.5 miljard Chatbot-toepassings is wêreldwyd toeganklik.
- Die top drie redes Amerikaanse verbruikers gebruik 'n kletsbot vir besigheidsure (18%), produkinligting (17%) en kliëntediensversoeke (16%).
Hierdie statistieke beklemtoon die toenemende aanvaarding en invloed van gespreks-KI oor verskeie industrieë en verbruikersgedrag.
Hoe werk Conversational AI
Gespreks-KI gebruik natuurlike taalverwerking (NLP) en ander gesofistikeerde algoritmes om aan konteksryke dialoë deel te neem. Aangesien die KI 'n groter reeks gebruikersinsette teëkom, verbeter dit sy patroonherkenning en voorspellingsvermoëns. Die proses van gespreks-KI om met gebruikers te skakel, kan in vier sleutelstappe opgedeel word:

Stap 1: Invoerversameling - Gebruikers lewer hul insette óf deur teks óf stem.
Stap 2: Invoerverwerking – Wanneer die invoer in teksvorm is, word natuurlike taalbegrip (NLU) gebruik om betekenis uit die woorde te onttrek. Vir steminvoere word outomatiese spraakherkenning (ASR) eers aangewend om oudio om te skakel na taaltokens wat verder ontleed kan word.
Stap 3: Reaksiegenerering – Natuurlike taalgenereringstegnieke word gebruik om gepas op die gebruiker se navraag te reageer.
Stap 4: Deurlopende verbetering – Gespreks-KI-stelsels ontleed gebruikersinsette oor tyd, en verfyn hul antwoorde om akkuraatheid en relevansie te verseker.



Versag algemene data-uitdagings in gesprekke-KI
Gespreks-KI is besig om mens-rekenaar kommunikasie dinamies te transformeer. En baie besighede is gretig om gevorderde KI-hulpmiddels en -toepassings te ontwikkel wat die manier waarop sake gedoen word, kan verander. Voordat u egter 'n kletsbot ontwikkel wat beter kommunikasie tussen u en u kliënte kan fasiliteer, moet u kyk na die vele ontwikkelingsslaggate wat u kan ondervind.
Taaldiversiteit
 Dit is uitdagend om 'n kletsassistent te ontwikkel wat in verskeie tale voorsiening kan maak. Boonop maak die blote diversiteit van globale tale dit 'n uitdaging om 'n kletsbot te ontwikkel wat naatloos kliëntediens aan alle kliënte verskaf.
Dit is uitdagend om 'n kletsassistent te ontwikkel wat in verskeie tale voorsiening kan maak. Boonop maak die blote diversiteit van globale tale dit 'n uitdaging om 'n kletsbot te ontwikkel wat naatloos kliëntediens aan alle kliënte verskaf.
In 2022, ongeveer 1.5 miljard mense het wêreldwyd Engels gepraat, gevolg deur Chinese Mandaryns met 1.1 miljard sprekers. Alhoewel Engels die mees gesproke en bestudeerde vreemde taal wêreldwyd is, is slegs ongeveer 20% van die wêreldbevolking praat dit. Dit maak dat die res van die wêreldbevolking – 80% – ander tale as Engels praat. Dus, wanneer u 'n kletsbot ontwikkel, moet u ook taaldiversiteit in ag neem.
Taalveranderlikheid
Mense praat verskillende tale en dieselfde taal verskillend. Ongelukkig is dit steeds onmoontlik vir 'n masjien om gesproke taalveranderlikheid ten volle te begryp, met inagneming van die emosies, dialekte, uitspraak, aksente en nuanses.
Ons woorde en taalkeuse word ook weerspieël in hoe ons tik. Daar kan van 'n masjien verwag word om die veranderlikheid van taal slegs te verstaan en te waardeer wanneer 'n groep annoteerders dit op verskeie spraakdatastelle oplei.
Dinamisme in spraak
Nog 'n groot uitdaging in die ontwikkeling van 'n gesprek-KI is om spraakdinamika in die stryd te bring. Ons gebruik byvoorbeeld verskeie vullers, pouses, sinfragmente en onontsyferbare klanke wanneer ons praat. Boonop is spraak baie meer kompleks as die geskrewe woord, aangesien ons nie gewoonlik tussen elke woord onderbreek en die regte lettergreep beklemtoon nie.
Wanneer ons na ander luister, is ons geneig om die bedoeling en betekenis van hul gesprek af te lei deur ons leeftyd se ervarings te gebruik. Gevolglik kontekstualiseer en begryp ons hul woorde, selfs wanneer dit dubbelsinnig is. 'n Masjien is egter nie in staat tot hierdie kwaliteit nie.
Lawaaierige data
Lawaaierige data of agtergrondgeraas is data wat nie waarde aan die gesprekke verskaf nie, soos deurklokkies, honde, kinders en ander agtergrondklanke. Daarom is dit noodsaaklik om die te skrop of te filtreer klank lêers van hierdie klanke en lei die KI-stelsel op om die klanke te identifiseer wat saak maak en dié wat nie.
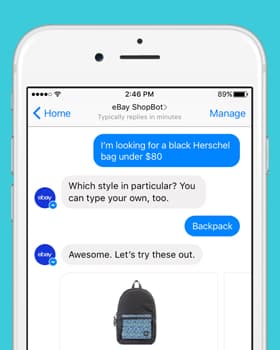
Voor- en nadele van verskillende spraakdatatipes
 Die bou van 'n KI-aangedrewe stemherkenningstelsel of 'n gespreks-KI vereis tonne opleiding en toetsdatastelle. Om toegang tot sulke kwaliteit datastelle te hê – betroubaar en voldoen aan jou spesifieke projekbehoeftes – is egter nie maklik nie. Tog is daar opsies beskikbaar vir besighede wat opleidingdatastelle soek, en elke opsie het voor- en nadele.
Die bou van 'n KI-aangedrewe stemherkenningstelsel of 'n gespreks-KI vereis tonne opleiding en toetsdatastelle. Om toegang tot sulke kwaliteit datastelle te hê – betroubaar en voldoen aan jou spesifieke projekbehoeftes – is egter nie maklik nie. Tog is daar opsies beskikbaar vir besighede wat opleidingdatastelle soek, en elke opsie het voor- en nadele.
As jy op soek is na 'n generiese datasteltipe, het jy baie openbare spraakopsies beskikbaar. Vir iets meer spesifiek en relevant vir jou projekvereiste, sal jy dit dalk op jou eie moet versamel en aanpas.
Eie spraakdata
Die eerste plek om te kyk is jou maatskappy se eie data. Aangesien u egter die wettige reg en toestemming het om u kliënt se spraakdata te gebruik, kan u hierdie massiewe datastel gebruik vir opleiding en toetsing van u projekte.
Pros:
- Geen bykomende opleidingsdata-insamelingskoste nie
- Die opleidingsdata is waarskynlik relevant vir jou besigheid
- Spraakdata het ook natuurlike omgewingsagtergrondakoestiek, dinamiese gebruikers en toestelle.
Nadele:
- Die gebruik van sulke data kan jou 'n klomp geld kos as jy toestemming kry om op te neem en te gebruik.
- Die spraakdata kan taal-, demografiese of klantebasisbeperkings hê
- Data is dalk gratis, maar jy sal steeds betaal vir die verwerking, transkripsie, merking en meer.
Openbare datastelle
Openbare spraakdatastelle is nog 'n opsie as jy nie van plan is om joune te gebruik nie. Hierdie datastelle is deel van die publieke domein en kan vir oopbronprojekte ingesamel word.
Pros:
- Openbare datastelle is gratis en ideaal vir laebegrotingprojekte
- Hulle is beskikbaar vir onmiddellike aflaai
- Publieke datastelle kom in 'n verskeidenheid geskrewe en ongeskrifte voorbeeldstelle voor.
Nadele:
- Die verwerkings- en kwaliteitversekeringskoste kan hoog wees
- Die kwaliteit van openbare spraakdatastelle verskil in 'n beduidende mate
- Die spraakmonsters wat aangebied word, is gewoonlik generies, wat hulle ongeskik maak vir die ontwikkeling van spesifieke spraakprojekte
- Die datastelle is tipies bevooroordeeld teenoor die Engelse taal
Vooraf verpakte/van die rak datastelle
Verken voorafverpakte datastelle is nog 'n opsie as publieke data of eie is spraakdata-insameling pas nie by jou behoeftes nie.
Die verkoper het voorafverpakte spraakdatastelle ingesamel vir die spesifieke doel om aan kliënte te verkoop. Hierdie tipe datastel kan gebruik word om generiese toepassings of spesifieke doeleindes te ontwikkel.
Pros:
- Jy kry dalk toegang tot 'n datastel wat by jou spesifieke spraakdatabehoefte pas
- Dit is meer bekostigbaar om 'n voorafverpakte datastel te gebruik as om jou eie te versamel
- Jy kan dalk vinnig toegang tot die datastel kry
Nadele:
- Aangesien die datastel vooraf verpak is, is dit nie aangepas by jou projekbehoeftes nie.
- Boonop is die datastel nie uniek aan u onderneming nie, aangesien enige ander onderneming dit kan koop.
Kies pasgemaakte versamelde datastelle
Wanneer u 'n spraaktoepassing bou, sal u 'n opleidingdatastel benodig wat aan al u spesifieke vereistes voldoen. Dit is egter hoogs onwaarskynlik dat jy toegang kry tot 'n voorafverpakte datastel wat aan die unieke vereistes van jou projek voldoen. Die enigste opsie wat beskikbaar is, is om jou datastel te skep of die datastel deur derdeparty-oplossingverskaffers te verkry.
Die datastelle vir jou opleiding- en toetsbehoeftes is heeltemal aanpasbaar. Jy kan taaldinamika, spraakdataverskeidenheid en toegang tot verskeie deelnemers insluit. Daarbenewens kan die datastel geskaal word om betyds aan u projekvereistes te voldoen.
Pros:
- Datastelle word vir jou spesifieke gebruiksgeval ingesamel. Die kans dat KI-algoritmes van die beoogde uitkomste afwyk, word tot die minimum beperk.
- Beheer en verminder vooroordeel in KI-data
Nadele:
- Die datastelle kan duur en tydrowend wees; die voordele weeg egter altyd swaarder as die koste.

Nywerhede wat Conversational KI gebruik
Tans word gesprekke-KI hoofsaaklik as Chatbots gebruik. Verskeie nywerhede implementeer egter hierdie tegnologie om groot voordele in te win. Sommige van die nywerhede wat gespreks-KI gebruik, is:
Healthcare
 Gespreks-KI het 'n groot impak op die gesondheidsorgsektor. Gespreks-KI het bewys dat dit voordelig is vir pasiënte, dokters, personeel, verpleegsters en ander mediese personeel.
Gespreks-KI het 'n groot impak op die gesondheidsorgsektor. Gespreks-KI het bewys dat dit voordelig is vir pasiënte, dokters, personeel, verpleegsters en ander mediese personeel.
Sommige van die voordele is
- Pasiëntbetrokkenheid in die na-behandelingsfase
- Afspraakskedulering chatbots
- Beantwoord gereelde vrae en algemene navrae
- Simptome assessering
- Identifiseer kritiekesorgpasiënte
- Eskalasie van noodgevalle
Ecommerce
 Gespreks-KI help e-handelondernemings om met hul kliënte te skakel, persoonlike aanbevelings te verskaf en produkte te verkoop.
Gespreks-KI help e-handelondernemings om met hul kliënte te skakel, persoonlike aanbevelings te verskaf en produkte te verkoop.
Die e-handelsbedryf benut die voordele van hierdie beste-in-klas tegnologie tot die uiterste.
- Versamel klantinligting
- Verskaf relevante produkinligting en aanbevelings
- Verbetering van kliëntetevredenheid
- Help om bestellings en terugsendings te plaas
- Beantwoord Gereelde Vrae
- Kruisverkoop en opverkope produkte
Bank
 Die banksektor is besig om gesprekke-KI-nutsmiddels te ontplooi om klantinteraksies te verbeter, versoeke intyds te verwerk en 'n vereenvoudigde en verenigde klantervaring oor verskeie kanale te bied.
Die banksektor is besig om gesprekke-KI-nutsmiddels te ontplooi om klantinteraksies te verbeter, versoeke intyds te verwerk en 'n vereenvoudigde en verenigde klantervaring oor verskeie kanale te bied.
- Laat kliënte toe om hul saldo's intyds na te gaan
- Help met deposito's
- Help met die indiening van belasting en die aansoek om lenings
- Stroomlyn die bankproses deur rekeningaanmanings, kennisgewings en waarskuwings te stuur
Versekering
 Soortgelyk aan die banksektor, word die versekeringsbedryf ook digitaal aangedryf deur gesprekke-KI en pluk die voordele daarvan. Gespreks-KI help byvoorbeeld die versekeringsbedryf om vinniger en meer betroubare maniere te bied om konflikte en eise op te los.
Soortgelyk aan die banksektor, word die versekeringsbedryf ook digitaal aangedryf deur gesprekke-KI en pluk die voordele daarvan. Gespreks-KI help byvoorbeeld die versekeringsbedryf om vinniger en meer betroubare maniere te bied om konflikte en eise op te los.
- Verskaf beleidsaanbevelings
- Vinniger eis skikkings
- Elimineer wagtye
- Versamel terugvoer en resensies van kliënte
- Skep klantebewustheid oor beleide
- Bestuur vinniger eise en hernuwing

Shaip Offer
As dit kom by die verskaffing van kwaliteit en betroubare datastelle vir die ontwikkeling van gevorderde mens-masjien-interaksie-spraaktoepassings, het Shaip die mark gelei met sy suksesvolle implementerings. Met 'n akute tekort aan kletsbotte en spraakassistente soek maatskappye egter toenemend die dienste van Shaip - die markleier - om pasgemaakte, akkurate en kwaliteit datastelle vir opleiding en toetsing vir KI-projekte te verskaf.
Deur natuurlike taalverwerking te kombineer, kan ons persoonlike ervarings verskaf deur te help om akkurate spraaktoepassings te ontwikkel wat menslike gesprekke effektief naboots. Ons gebruik 'n rits hoë-end tegnologieë om hoë gehalte klante-ervarings te lewer. NLP leer masjiene om menslike tale te interpreteer en met mense om te gaan.
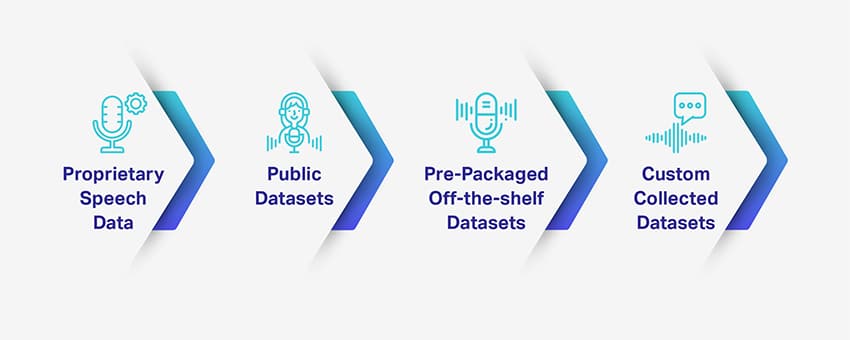
Oudio-transkripsie
Shaip is 'n toonaangewende oudiotranskripsiediensverskaffer wat 'n verskeidenheid spraak-/klanklêers vir alle soorte projekte bied. Boonop bied Shaip 'n 100% mensgegenereerde transkripsiediens om oudio- en videolêers – onderhoude, seminare, lesings, poduitsendings, ens. in maklik leesbare teks om te skakel.
Spraaketikettering
Shaip bied uitgebreide spraaketiketteringsdienste deur die klanke en spraak kundig in 'n oudiolêer te skei en elke lêer te benoem. Deur soortgelyke klankklanke akkuraat te skei en dit te annoteer,
Luidspreker se dagboek
Sharp se kundigheid strek tot die aanbied van uitstekende luidspreker-diariseringsoplossings deur die klankopname te segmenteer op grond van hul bron. Verder word die luidsprekergrense akkuraat geïdentifiseer en geklassifiseer, soos luidspreker 1, luidspreker 2, musiek, agtergrondgeraas, voertuigklanke, stilte, en meer, om die aantal luidsprekers te bepaal.
Klankindeling
Annotasie begin met die klassifikasie van oudiolêers in voorafbepaalde kategorieë. Die kategorieë hang hoofsaaklik af van die projek se vereistes, en dit sluit tipies gebruikersvoorneme, taal, semantiese segmentering, agtergrondgeraas, die totale aantal sprekers en meer in.
Natuurlike taaluitingversameling/ wakkerwordwoorde
Dit is moeilik om te voorspel dat die kliënt altyd soortgelyke woorde sal kies wanneer hy 'n vraag vra of 'n versoek inisieer. Bv. "Waar is die naaste restaurant?" "Vind restaurante naby my" of "Is daar 'n restaurant naby?"
Al drie uitinge het dieselfde bedoeling, maar is anders geformuleer. Deur middel van permutasie en kombinasie sal die kundige gesprek-ai-spesialiste by Shaip al die moontlike kombinasies identifiseer om dieselfde versoek te verwoord. Shaip versamel en annoteer uitsprake en wakker woorde, met die fokus op semantiek, konteks, toon, diksie, tydsberekening, klem en dialekte.
Veeltalige klankdatadienste
Veeltalige oudiodatadienste is nog 'n aanbieding van Shaip wat baie voorkeur geniet, aangesien ons 'n span dataversamelaars het wat oudiodata in meer as 150 tale en dialekte regoor die wêreld versamel.
Voorneme opsporing
Menslike interaksies en kommunikasie is dikwels meer ingewikkeld as waarvoor ons hulle krediet gee. En hierdie ingebore komplikasie maak dit moeilik om 'n ML-model op te lei om menslike spraak akkuraat te verstaan.
Boonop kan verskillende mense van dieselfde demografiese of verskillende demografiese groepe dieselfde voorneme of sentiment verskillend uitdruk. Dus, die spraakherkenningstelsel moet opgelei word om gemeenskaplike voorneme te erken, ongeag die demografiese.
Om te verseker dat jy 'n top-notch ML-model kan oplei en ontwikkel, verskaf ons spraakterapeute uitgebreide en diverse datastelle om die stelsel te help om die verskeie maniere te identifiseer waarop mense dieselfde voorneme uitdruk.
Bedoelingsklassifikasie
Soortgelyk aan die identifisering van dieselfde voorneme van verskillende mense, moet jou kletsbotte ook opgelei word om klantopmerkings in verskillende kategorieë te kategoriseer – vooraf deur jou bepaal. Elke kletsbot of virtuele assistent is ontwerp en ontwikkel met 'n spesifieke doel. Shaip kan gebruikersvoorneme in voorafbepaalde kategorieë klassifiseer soos benodig.
Outomatiese spraakherkenning of ASR
Spraakherkenning” verwys na die omskakeling van gesproke woorde in die teks; stemherkenning en sprekeridentifikasie het egter ten doel om beide gesproke inhoud en die spreker se identiteit te identifiseer. ASR se akkuraatheid word bepaal deur verskillende parameters, dit wil sê, luidsprekervolume, agtergrondgeraas, opnametoerusting, ens.
Toonopsporing
Nog 'n interessante faset van menslike interaksie is toon – ons herken intrinsiek die betekenis van woorde na gelang van die toon waarmee dit uitgespreek word. Alhoewel wat ons sê belangrik is, dra hoe ons daardie woorde sê ook betekenis oor.
Byvoorbeeld, 'n eenvoudige frase soos 'Watter vreugde!' kan 'n uitroep van geluk wees en kan ook bedoel wees om sarkasties te wees. Dit hang af van die toon en stres.
'Wat maak jy?'
'Wat maak jy?'
Beide hierdie sinne het die presiese woorde, maar die klem op die woorde is anders, wat die hele betekenis van die sinne verander. Die kletsbot is opgelei om geluk, sarkasme, woede, irritasie en meer uitdrukkings te identifiseer. Dit is waar die kundigheid van Sharp se spraak-taalpatoloë en annoteerders ter sprake kom.
Oudio- / Spraakdatalisensiëring
Shaip bied ongeëwenaarde spraakdatastelle van gehalte van die rak wat aangepas kan word om by jou projek se spesifieke behoeftes te pas. Die meeste van ons datastelle kan by elke begroting pas, en die data is skaalbaar om aan alle toekomstige projekvereistes te voldoen. Ons bied meer as 40 100 uur se spraakdatastelle van die rak in meer as 50 dialekte in meer as XNUMX tale. Ons bied ook 'n reeks oudiotipes, insluitend spontane, monoloog, geskrewe en wakker woorde. Bekyk die hele Data Katalogus.
Oudio- / Spraakdata-insameling
Wanneer daar 'n tekort aan kwaliteit spraakdatastelle is, kan die gevolglike spraakoplossing deurspek wees met probleme en 'n gebrek aan betroubaarheid. Shaip is een van die min verskaffers wat veeltalige oudioversamelings, oudiotranskripsie en annotasie gereedskap en dienste wat volledig aanpasbaar is vir die projek.
Spraakdata kan as 'n spektrum beskou word, wat gaan van natuurlike spraak aan die een kant tot onnatuurlike spraak aan die ander kant. In natuurlike spraak het jy die spreker wat op 'n spontane wyse praat. Aan die ander kant, onnatuurlike spraakklanke word beperk as die spreker besig is om 'n skrif af te lees. Laastens word sprekers aangespoor om woorde of frases op 'n beheerde wyse in die middel van die spektrum uit te spreek.
Sharp se kundigheid strek tot die verskaffing van verskillende tipes spraakdatastelle in meer as 150 tale

































Sukses Stories
Ons het met sommige van die topbesighede en handelsmerke gewerk en hulle voorsien van gespreks-KI-oplossings van die hoogste orde.
Sommige van ons suksesverhale sluit in,
- Ons het 'n spraakherkenningsdatastel ontwikkel met meer as 10,000 XNUMX uur se veeltalige transkripsies, gesprekke en oudiolêers om 'n regstreekse kletsbot op te lei en te bou.
- Ons het 'n hoëgehalte-datastel van 1000'e gesprekke van 6 beurte per gesprek gebou wat vir versekering-kletsbotopleiding gebruik word.
- Ons span van meer as 3000 1000 taalkundiges het meer as 27 XNUMX uur se oudiolêers en transkripsies in XNUMX inheemse tale verskaf vir opleiding en toetsing van 'n digitale assistent.
- Ons span annoteerders en taalkundiges het ook 20,000 27 en meer ure se uitsprake in meer as XNUMX wêreldtale vinnig ingesamel en gelewer.
- Ons outomatiese spraakherkenningsdienste is een van die industrie wat die meeste verkies. Ons het betroubare benoemde oudiolêers verskaf, wat spesifieke aandag aan uitspraak, toon en bedoeling verseker het deur 'n wye reeks transkripsies en leksikon van uiteenlopende luidsprekerstelle te gebruik om die betroubaarheid van ASR-modelle te verbeter.
Ons suksesverhale spruit uit die verbintenis van ons span om altyd die beste dienste aan ons kliënte te verskaf deur die nuutste tegnologieë te gebruik. Wat ons anders maak, is dat ons werk gerugsteun word deur kundige annoteerders wat onbevooroordeelde en akkurate datastelle van goudstandaard-aantekeninge verskaf.
Ons data-insamelingspan van meer as 30,000 bydraers kan datastelle van hoë gehalte verkry, skaal en lewer wat help met die vinnige ontplooiing van ML-modelle. Boonop werk ons op die nuutste KI-gebaseerde platform en het ons die vermoë om versnelde spraakdata-oplossings baie vinniger aan besighede te verskaf as ons naaste mededingers.
