



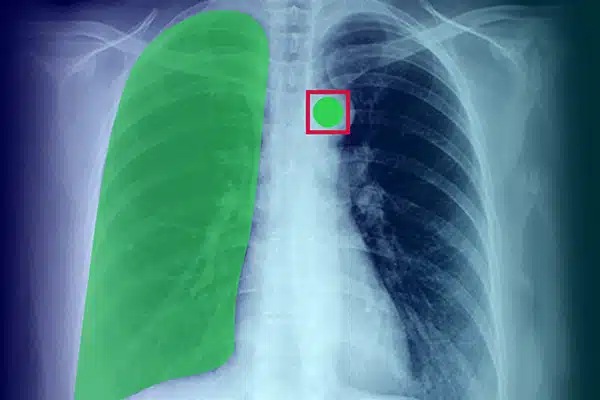
Beeldaantekening
Verbeter mediese KI deur visuele data van X-strale, CT-skanderings en MRI's aan te teken. Verseker KI-modelle presteer uitstekend in diagnostiek en behandeling, gelei deur kundige data-etikettering. Kry beter pasiëntuitkomste met uitstekende beelding-insigte.
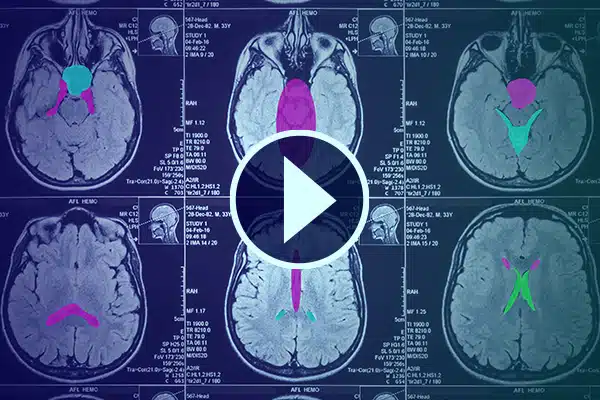
Video-aantekening
Bevorder KI in gesondheidsorg met gedetailleerde video-aantekeninge. Verskerp KI-leer met klassifikasies en segmentasies in mediese beeldmateriaal. Verbeter jou chirurgiese KI en pasiëntmonitering vir verbeterde gesondheidsorglewering en diagnostiek.
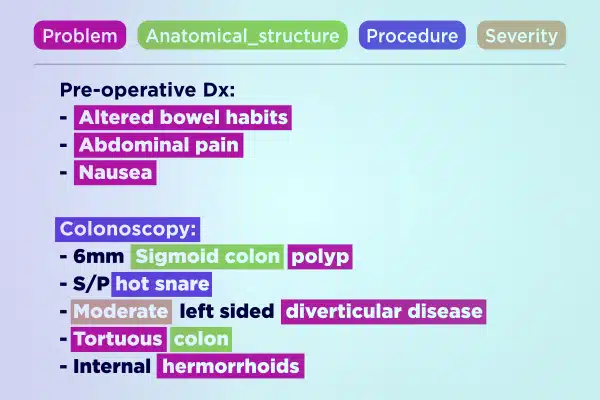
Teksaantekening
Stroomlyn mediese KI-ontwikkeling met kundig geannoteerde teksdata. Ontleed en verryk vinnig groot teksvolumes, van handgeskrewe notas tot versekeringsverslae. Verseker akkurate en uitvoerbare insigte vir gesondheidsorgvorderings.

Klankaantekening
Gebruik NLP-kundigheid om mediese oudiodata akkuraat te annoteer en te benoem. Skep stemondersteunde stelsels vir naatlose kliniese bedrywighede en integreer KI in verskeie stemgeaktiveerde gesondheidsorgprodukte. Verbeter diagnostiese akkuraatheid met kundige klankdata-kurasie.

Mediese kodering
Stroomlyn mediese dokumentasie deur dit om te skakel in universele kodes met KI mediese kodering. Verseker akkuraatheid, verbeter faktureringsdoeltreffendheid en ondersteun naatlose gesondheidsorgdienslewering met die nuutste KI-bystand in mediese rekordkodering.

Fase 1: Tegniese domeinkundigheid (Verstaan omvang en annotasieriglyne)

Fase 2: Opleiding van toepaslike hulpbronne vir die projek

Fase 3: Terugvoersiklus en QA van die geannoteerde dokumente
Radiologie
Ons radiologie-beeldaantekeningdiens verskerp KI-diagnostiek en sluit 'n bykomende laag kundigheid in. Elke X-straal-, MRI- en CT-skandering word noukeurig gemerk en hersien deur 'n vakkundige. Hierdie ekstra stap in opleiding en hersiening verhoog die KI se vermoë om abnormaliteite en siektes op te spoor. Dit verbeter akkuraatheid voor aflewering aan ons kliënte.

Kardiologie
Ons kardiologie-gefokusde beeldannotasie verskerp KI-diagnostiek. Ons bring kardiologiekundiges in wat komplekse hartverwante beelde etiketteer en ons KI-modelle oplei. Voordat ons data aan kliënte stuur, hersien hierdie spesialiste elke prent om die hoogste akkuraatheid te verseker. Hierdie proses bemagtig KI om harttoestande meer presies op te spoor.
Tandheelkunde
Ons beeldaantekeningdiens in tandheelkunde benoem tandheelkundige beelde om KI-diagnostiese hulpmiddels te verbeter. Deur tandbederf, belyningskwessies en ander tandtoestande akkuraat te identifiseer, bemagtig ons KMO's KI om pasiëntuitkomste te verbeter en tandartse te ondersteun in presiese behandelingsbeplanning en vroeë opsporing.


















Mense
Toegewyde en opgeleide spanne:
- 30,000+ medewerkers vir die skep van data, etikettering en QA
- Gesertifiseerde projekbestuurspan
- Ervare produkontwikkelingspan
- Talent Pool Sourcing & Onboarding Team

proses
Die hoogste doeltreffendheid van die proses word verseker deur:
- Robuuste 6 Sigma Stage-Gate-proses
- 'N Toegewyde span van 6 Sigma swart gordels - Belangrike prosesseienaars en voldoening aan gehalte
- Deurlopende verbetering en terugvoerlus

platform
Die gepatenteerde platform bied voordele:
- Web-gebaseerde end-to-end platform
- Onberispelike kwaliteit
- Vinniger TAT
- Naadloze aflewering



