Inleiding
 Kunsmatige intelligensie gaan alles oor die gebruik van masjiene om die lewe en lewenstyl van mense te verhoog deur hul alledaagse lewens interessante en oorbodige take eenvoudig te maak. KI is nooit veronderstel om 'n oorheersende krag te wees nie, maar 'n komplementêre een wat in tandem met mense werk om die ongeloofwaardige op te los en die weg te baan vir kollektiewe evolusie.
Kunsmatige intelligensie gaan alles oor die gebruik van masjiene om die lewe en lewenstyl van mense te verhoog deur hul alledaagse lewens interessante en oorbodige take eenvoudig te maak. KI is nooit veronderstel om 'n oorheersende krag te wees nie, maar 'n komplementêre een wat in tandem met mense werk om die ongeloofwaardige op te los en die weg te baan vir kollektiewe evolusie.
Van nou af stap ons op die regte pad met beduidende deurbrake wat oor nywerhede plaasvind met behulp van KI. As jy byvoorbeeld gesondheidsorg neem, help KI-stelsels wat deur masjienleermodelle vergesel word kundiges om kanker beter te verstaan en met behandelings daarvoor vorendag te kom. Neurologiese afwykings en bekommernisse soos PTSV word met behulp van KI behandel. Entstowwe word teen vinnige tempo ontwikkel danksy KI-aangedrewe kliniese proewe en simulasies.
Nie net gesondheidsorg nie, elke bedryf of segment wat KI raak, word 'n omwenteling ondergaan. Outonome voertuie, slim geriefswinkels, draagbare items soos FitBit en selfs ons slimfoonkameras is in staat om beter beelde van ons gesigte met KI vas te lê.
Danksy die innovasies wat in die KI-ruimte plaasvind, vaar maatskappye in die spektrum met verskeie gebruiksgevalle en oplossings. As gevolg hiervan word verwag dat die wêreldwye KI-mark teen die einde van 267 'n markwaarde van ongeveer $2027 miljard sal bereik. Boonop implementeer ongeveer 37% van die besighede daar buite reeds KI-oplossings in hul prosesse en produkte.
Meer interessant, byna 77% van die produkte en dienste wat ons vandag gebruik word deur KI aangedryf. Met die tegnologiese konsep wat aansienlik styg oor vertikale, hoe kry besighede dit reg om onmoontlik met KI te doen?

 Hoe voorspel toestelle so eenvoudig soos 'n horlosie hartaanvalle by mense akkuraat? Hoe is dit moontlik dat motors en motors wat nog altyd 'n bestuurder vereis het, skielik minder op paaie ry?
Hoe voorspel toestelle so eenvoudig soos 'n horlosie hartaanvalle by mense akkuraat? Hoe is dit moontlik dat motors en motors wat nog altyd 'n bestuurder vereis het, skielik minder op paaie ry?
Hoe laat chatbots ons glo dat ons met 'n ander mens aan die ander kant praat?
As jy die antwoord op elke vraag waarneem, kom dit neer op net een element – DATA. Data lê in die middel van alle KI-spesifieke bedrywighede en prosesse. Dit is data wat masjiene help om konsepte te verstaan, insette te verwerk en akkurate resultate te lewer.
Al die belangrikste KI-oplossings wat daar is, is almal produkte van 'n deurslaggewende proses wat ons data-insameling of data-verkryging of KI-opleidingsdata noem.
Hierdie uitgebreide gids gaan alles daaroor om jou te help verstaan wat dit is en hoekom dit belangrik is.
Wat is KI-data-insameling?
Masjiene het nie hul eie verstand nie. Die afwesigheid van hierdie abstrakte konsep maak hulle sonder opinies, feite en vermoëns soos redenering, kognisie en meer. Hulle is net vaste bokse of toestelle wat ruimte in beslag neem. Om dit in kragtige mediums te verander, benodig jy algoritmes en meer belangrik data.
 Die algoritmes wat ontwikkel word, het iets nodig om aan te werk en te verwerk en daardie iets is data wat relevant, kontekstueel en onlangs is. Die proses om sulke data in te samel vir masjiene om hul beoogde doeleindes te dien, word KI-data-insameling genoem.
Die algoritmes wat ontwikkel word, het iets nodig om aan te werk en te verwerk en daardie iets is data wat relevant, kontekstueel en onlangs is. Die proses om sulke data in te samel vir masjiene om hul beoogde doeleindes te dien, word KI-data-insameling genoem.
Elke enkele KI-geaktiveerde produk of oplossing wat ons vandag gebruik en die resultate wat hulle bied spruit uit jare se opleiding, ontwikkeling en optimalisering. Van toestelle wat navigasieroetes bied tot daardie komplekse stelsels wat dae vooruit toerusting mislukking voorspel, elke enkele entiteit het jare se KI-opleiding deurgemaak om akkuraat resultate te kan lewer.
KI data-insameling is die voorlopige stap in die proses van KI-ontwikkeling wat reg van die begin af bepaal hoe effektief en doeltreffend 'n KI-stelsel sal wees. Dit is die proses om relevante datastelle uit 'n magdom bronne te verkry wat KI-modelle sal help om besonderhede beter te verwerk en betekenisvolle resultate te kry.




Hoe om data in te samel vir 'n masjienleer?
 Dit is waar dinge 'n bietjie moeilik begin raak. Van die begin af wil dit voorkom asof jy 'n oplossing vir 'n werklike probleem in gedagte het, jy weet KI sal die ideale manier wees om dit te doen en jy het jou modelle ontwikkel. Maar nou is jy in die deurslaggewende fase waar jy met jou KI-opleidingsprosesse moet begin. Jy benodig oorvloedige KI-opleidingsdata saam met jou om jou modelle konsepte te laat leer en resultate te lewer. U het ook valideringsdata nodig om u resultate te toets en u algoritmes te optimaliseer.
Dit is waar dinge 'n bietjie moeilik begin raak. Van die begin af wil dit voorkom asof jy 'n oplossing vir 'n werklike probleem in gedagte het, jy weet KI sal die ideale manier wees om dit te doen en jy het jou modelle ontwikkel. Maar nou is jy in die deurslaggewende fase waar jy met jou KI-opleidingsprosesse moet begin. Jy benodig oorvloedige KI-opleidingsdata saam met jou om jou modelle konsepte te laat leer en resultate te lewer. U het ook valideringsdata nodig om u resultate te toets en u algoritmes te optimaliseer.
So, hoe kry jy jou data? Watter data het jy nodig en hoeveel daarvan? Wat is die veelvuldige bronne om relevante data te gaan haal?
Maatskappye beoordeel die nis en doel van hul ML-modelle en skets potensiële maniere om relevante datastelle te verkry. Om die datatipe te definieer wat nodig is, los 'n groot deel van jou bekommernis oor dataverkryging op. Om jou 'n beter idee te gee, is daar verskillende kanale, weë, bronne of mediums vir data-insameling:
Hoe beïnvloed slegte data jou KI-ambisies?
Ons het die drie mees algemene databronne gelys om die rede dat jy 'n idee sal hê oor hoe om data-insameling en -verkryging te benader. Op hierdie stadium word dit egter noodsaaklik om ook te verstaan dat jou besluit altyd die lot van jou KI-oplossing kan bepaal.
Soortgelyk aan hoe hoë kwaliteit KI-opleidingsdata jou model kan help om akkurate en tydige resultate te lewer, kan slegte opleidingsdata ook jou KI-modelle breek, resultate skeeftrek, vooroordeel inbring en ander ongewenste gevolge bied.
Maar hoekom gebeur dit? Is enige data nie veronderstel om jou KI-model op te lei en te optimaliseer nie? Eerlik, nee. Kom ons verstaan dit verder.
Slegte data – wat is dit?
 Slegte data is enige data wat irrelevant, verkeerd, onvolledig of bevooroordeeld is. Danksy swak gedefinieerde data-insamelingstrategieë het die meeste datawetenskaplikes en annotasie kundiges word gedwing om aan slegte data te werk.
Slegte data is enige data wat irrelevant, verkeerd, onvolledig of bevooroordeeld is. Danksy swak gedefinieerde data-insamelingstrategieë het die meeste datawetenskaplikes en annotasie kundiges word gedwing om aan slegte data te werk.
Die verskil tussen ongestruktureerde en slegte data is dat insigte in ongestruktureerde data oral is. Maar in wese kan hulle nuttig wees ongeag. Deur bykomende tyd te spandeer, sal datawetenskaplikes steeds relevante inligting uit ongestruktureerde datastelle kan onttrek. Dit is egter nie die geval met slegte data nie. Hierdie datastelle bevat geen/beperkte insigte of inligting wat waardevol of relevant is vir jou KI-projek of sy opleidingsdoeleindes nie.
Dus, wanneer jy jou datastelle uit gratis bronne verkry of losweg vasgestelde interne data raakpunte het, is die kans hoogs waarskynlik dat jy slegte data sal aflaai of genereer. Wanneer jou wetenskaplikes aan slegte data werk, mors jy nie net menslike ure nie, maar stoot jy ook die bekendstelling van jou produk aan.
As jy nog onduidelik is oor wat slegte data aan jou ambisies kan doen, hier is 'n vinnige lys:
- Jy spandeer ontelbare ure om die slegte data te bekom en mors ure, moeite en geld op hulpbronne.
- Slegte data kan jou regsprobleme oplewer, indien onopgemerk en kan die doeltreffendheid van jou KI afneem
modelle. - Wanneer jy jou produk wat op slegte data opgelei is, regstreeks neem, beïnvloed dit gebruikerservaring
- Slegte data kan resultate en afleidings bevooroordeeld maak, wat verdere terugslae kan veroorsaak.
So, as jy wonder of daar 'n oplossing hiervoor is, is daar eintlik.
KI Opleiding Dataverskaffers tot die redding
 Een van die basiese oplossings is om vir 'n dataverkoper (betaalde bronne) te gaan. Verskaffers van KI-opleidingsdata verseker dat dit wat u ontvang akkuraat en relevant is en dat u datastelle in 'n gestruktureerde vorm aan u afgelewer het. Jy hoef nie betrokke te wees by die rompslomp om van portaal na portaal te beweeg op soek na datastelle nie.
Een van die basiese oplossings is om vir 'n dataverkoper (betaalde bronne) te gaan. Verskaffers van KI-opleidingsdata verseker dat dit wat u ontvang akkuraat en relevant is en dat u datastelle in 'n gestruktureerde vorm aan u afgelewer het. Jy hoef nie betrokke te wees by die rompslomp om van portaal na portaal te beweeg op soek na datastelle nie.
Al wat jy hoef te doen is om die data in te neem en jou KI-modelle op te lei vir perfeksie. Met dit gesê, is ons seker jou volgende vraag is oor die uitgawes verbonde aan samewerking met dataverskaffers. Ons verstaan dat sommige van julle reeds aan 'n verstandelike begroting werk en dit is presies waarheen ons ook volgende op pad is.
Faktore om in ag te neem wanneer 'n effektiewe begroting vir u data-insamelingsprojek vorendag kom
KI-opleiding is 'n sistematiese benadering en daarom word begroting 'n integrale deel daarvan. Faktore soos RoI, akkuraatheid van resultate, opleidingsmetodologieë en meer moet oorweeg word voordat 'n groot bedrag geld in KI-ontwikkeling belê word. Baie projekbestuurders of sake-eienaars vroetel in hierdie stadium. Hulle neem oorhaastige besluite wat onomkeerbare veranderinge in hul produkontwikkelingsproses meebring, wat hulle uiteindelik dwing om meer te bestee.
Hierdie afdeling sal jou egter die regte insigte gee. Wanneer jy gaan sit om aan die begroting vir KI-opleiding te werk, is drie dinge of faktore onvermydelik.

Kom ons kyk na elkeen in detail.
Die volume data wat jy benodig
Ons het al die tyd gesê dat die doeltreffendheid en akkuraatheid van jou KI-model afhang van hoeveel dit opgelei is. Dit beteken dat hoe meer die volume van datastelle, hoe meer die leer. Maar dit is baie vaag. Om 'n nommer op hierdie idee te plaas, het Dimensional Research 'n verslag gepubliseer wat aan die lig gebring het dat besighede 'n minimum van 100,000 XNUMX voorbeelddatastelle benodig om hul KI-modelle op te lei.
Met 100,000 100,000 datastelle bedoel ons XNUMX XNUMX kwaliteit en relevante datastelle. Hierdie datastelle moet al die noodsaaklike eienskappe, aantekeninge en insigte hê wat nodig is vir jou algoritmes en masjienleermodelle om inligting te verwerk en beoogde take uit te voer.
Met hierdie is 'n algemene reël, laat ons verder verstaan dat die volume data wat jy nodig het ook afhang van 'n ander ingewikkelde faktor wat jou besigheid se gebruiksgeval is. Wat jy van plan is om met jou produk of oplossing te doen, bepaal ook hoeveel data jy benodig. Byvoorbeeld, 'n besigheid wat 'n aanbevelingsenjin bou, sal ander datavolumevereistes hê as 'n maatskappy wat 'n kletsbot bou.
Dataprysstrategie
Wanneer jy klaar gefinaliseer het hoeveel data jy werklik nodig het, moet jy volgende werk aan 'n dataprysstrategie. Dit, in eenvoudige terme, beteken hoe jy sou betaal vir die datastelle wat jy verkry of genereer.
Oor die algemeen is dit die konvensionele prysstrategieë wat in die mark gevolg word:
| Datatipe | Prysstrategie |
|---|---|
| Geprys per enkele beeldlêer | |
| Geprys per sekonde, minuut, 'n uur of individuele raamwerk | |
| Geprys per sekonde, 'n minuut of uur | |
| Geprys per woord of sin |
Maar wag. Dit is weer 'n reël. Die werklike koste van die verkryging van datastelle hang ook af van faktore soos:
- Die unieke marksegment, demografie of geografie waaruit datastelle verkry moet word
- Die ingewikkeldheid van jou gebruiksgeval
- Hoeveel data benodig jy?
- Jou tyd om te bemark
- Enige pasgemaakte vereistes en meer
As jy waarneem, sal jy weet dat die koste om grootmaat hoeveelhede beelde vir jou KI-projek te bekom minder kan wees, maar as jy te veel spesifikasies het, kan die pryse styg.
Jou verkrygingstrategieë
Dit is moeilik. Soos jy gesien het, is daar verskillende maniere om data vir jou KI-modelle te genereer of te verkry. Gesonde verstand sal bepaal dat gratis hulpbronne die beste is, aangesien u die vereiste volumes datastelle gratis kan aflaai sonder enige komplikasies.
Op die oomblik wil dit ook voorkom asof betaalde bronne te duur is. Maar dit is waar 'n laag komplikasies bygevoeg word. Wanneer jy datastelle van gratis hulpbronne verkry, spandeer jy 'n bykomende hoeveelheid tyd en moeite om jou datastelle skoon te maak, dit saam te stel in jou besigheidspesifieke formaat en dan individueel aan te teken. Jy gaan operasionele koste in die proses aan.
Met betaalde bronne is die betaling eenmalig en jy kry ook masjiengereed datastelle in die hand op die tyd wat jy benodig. Die koste-effektiwiteit is hier baie subjektief. As jy voel jy kan bekostig om tyd te spandeer om gratis datastelle te annoteer, kan jy dienooreenkomstig begroot. En as jy glo jou mededinging is fel en met beperkte tyd om te bemark, kan jy 'n rimpeleffek in die mark skep, moet jy betaalde bronne verkies.
Begroting gaan alles daaroor om die besonderhede af te breek en elke fragment duidelik te definieer. Hierdie drie faktore behoort jou in die toekoms as 'n padkaart vir jou KI-opleidingsbegrotingsproses te dien.
Spaar jy op uitgawes met interne dataverkryging?
 Terwyl ons begroot het, het ons ondersoek hoe gratis hulpbronne jou dwing om op die langer termyn meer te bestee. Op daardie stadium sou jy outomaties gewonder het oor die koste-effektiwiteit van die interne data-verkrygingsproses.
Terwyl ons begroot het, het ons ondersoek hoe gratis hulpbronne jou dwing om op die langer termyn meer te bestee. Op daardie stadium sou jy outomaties gewonder het oor die koste-effektiwiteit van die interne data-verkrygingsproses.
Ons weet dat jy steeds huiwerig is oor betaalde bronne en daarom sal hierdie afdeling jou skeptisisme daaroor uit die weg ruim en lig werp op die verborge koste verbonde aan die generering van interne data.
Is interne dataverkryging duur?
Ja dit is!
Nou, hier is 'n uitgebreide antwoord. Uitgawe is enigiets wat jy spandeer. Terwyl ons gratis hulpbronne bespreek het, het ons onthul dat u geld, tyd en moeite in die proses spandeer. Dit geld ook vir interne data-verkryging.
 As gevolg van die feit dat jy pasgemaakte raakpunte of data tregters het, beteken dit nie dat jy sou hê nie masjiengereed datastelle op die ou end. Die data wat jy genereer sal steeds meestal rou en ongestruktureerd wees. Jy het dalk al die data wat jy nodig het op een plek, maar wat die data bevat sal oral wees.
As gevolg van die feit dat jy pasgemaakte raakpunte of data tregters het, beteken dit nie dat jy sou hê nie masjiengereed datastelle op die ou end. Die data wat jy genereer sal steeds meestal rou en ongestruktureerd wees. Jy het dalk al die data wat jy nodig het op een plek, maar wat die data bevat sal oral wees.
Uiteindelik sal u uiteindelik bestee aan die betaling van u werknemers, datawetenskaplikes, annoteerders, gehalteversekeringspersoneel en meer. Jy sal ook bestee aan intekeninge vir annotasie-nutsgoed en
instandhouding van CMS, CRM en ander infrastruktuur uitgawes.
Boonop het datastelle waarskynlik besorgdheid oor vooroordeel en akkuraatheid, wat u nodig het om dit handmatig te sorteer. En as jy 'n slytasieprobleem in jou KI-opleidingsdataspan het, sal jy moet spandeer om nuwe lede te werf, hulle te oriënteer op jou prosesse, hulle op te lei om jou gereedskap te gebruik en meer.
Jy sal uiteindelik meer spandeer as wat jy uiteindelik op die langer termyn sou maak. Daar is ook annotasie-uitgawes. Op enige gegewe tydstip is die totale koste wat aangegaan word om met interne data te werk:
Koste aangegaan = Aantal annoteerders * Koste per annoteerder + Platformkoste
As jou KI-opleidingskalender vir maande geskeduleer is, stel jou voor die uitgawes wat jy konsekwent sou aangaan. Dus, is dit die ideale oplossing vir bekommernisse oor dataverkryging of is daar enige alternatief?
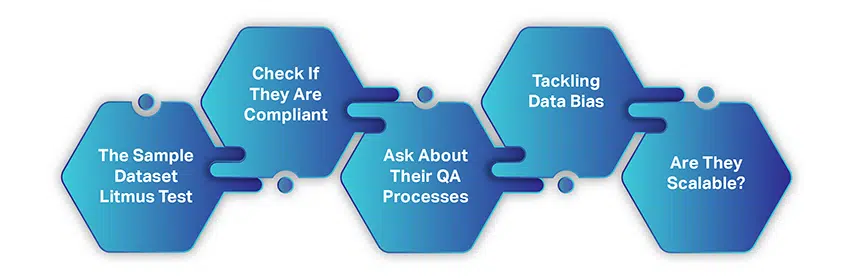
Hoe om die regte AI Data Collection Company te kies
Die keuse van 'n KI-data-insamelingsmaatskappy is nie so ingewikkeld of tydrowend soos om data uit gratis hulpbronne in te samel nie. Daar is net 'n paar eenvoudige faktore wat jy moet oorweeg en dan hande skud vir 'n samewerking.
Wanneer jy begin soek na 'n dataverkoper, neem ons aan dat jy alles wat ons tot dusver bespreek het gevolg en oorweeg het. Hier is egter 'n vinnige opsomming:
- Jy het 'n goed gedefinieerde gebruiksgeval in gedagte
- Jou marksegment en datavereistes is duidelik vasgestel
- Jou begroting is op die punt
- En jy het 'n idee van die volume data wat jy nodig het
Met hierdie items afgemerk, laat ons verstaan hoe jy 'n ideale diensverskaffer vir opleidingsdata kan soek.