
Inleiding
Hierdie gids sal uiters nuttig wees vir kopers en besluitnemers wat hul gedagtes na die moere en boute van data-verkryging en data-implementering vir neurale netwerke en ander vorme van AI- en ML-bedrywighede begin rig.

Hierdie artikel is volledig daarop gemik om lig te werp op wat die proses is, waarom dit onvermydelik, noodsaaklik is
faktore wat ondernemings moet oorweeg wanneer hulle data -annotasie -instrumente en meer benader. Dus, as u 'n besigheid besit, moet u inlig, aangesien hierdie gids u sal lei deur alles wat u moet weet oor data -aantekeninge.
Laat ons begin.
Hier is 'n paar vinnige wegneemetes wat u in die gids kan vind:
- Verstaan wat data-aantekening is
- Ken die verskillende soorte data-aantekeningsprosesse
- Ken die voordele van die implementering van die data -annotasieproses
- Kry duidelikheid of u interne data-etikettering moet gebruik of dit moet uitkontrakteer
- Insigte oor die keuse van die regte data-aantekening
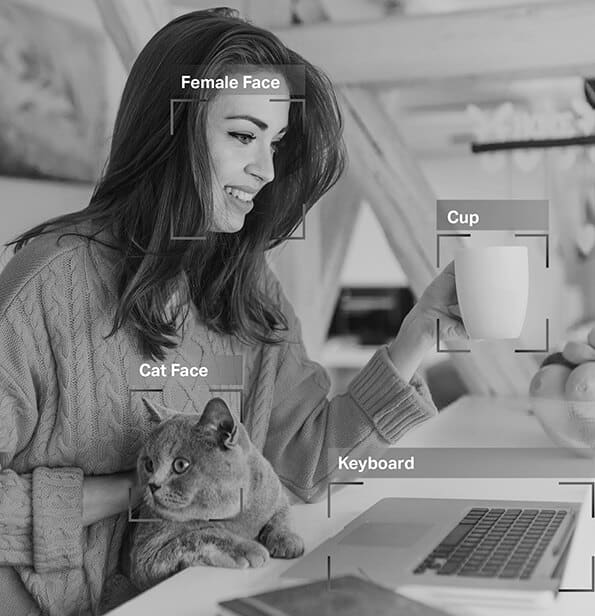
Wat is masjienleer?
 Ons het gepraat oor hoe data -aantekeninge of data -etikettering masjienleer ondersteun en dat dit bestaan uit die merk of identifisering van komponente. Maar wat diep leer en masjienleer self betref: die basiese uitgangspunt van masjienleer is dat rekenaarstelsels en programme hul uitsette kan verbeter op maniere wat soos menslike kognitiewe prosesse lyk, sonder direkte menslike hulp of ingryping, om ons insigte te gee. Met ander woorde, dit word selfleermasjiene wat, net soos 'n mens, met hul oefening beter in hul werk word. Hierdie 'praktyk' word verkry deur meer (en beter) opleidingsdata te ontleed en te interpreteer.
Ons het gepraat oor hoe data -aantekeninge of data -etikettering masjienleer ondersteun en dat dit bestaan uit die merk of identifisering van komponente. Maar wat diep leer en masjienleer self betref: die basiese uitgangspunt van masjienleer is dat rekenaarstelsels en programme hul uitsette kan verbeter op maniere wat soos menslike kognitiewe prosesse lyk, sonder direkte menslike hulp of ingryping, om ons insigte te gee. Met ander woorde, dit word selfleermasjiene wat, net soos 'n mens, met hul oefening beter in hul werk word. Hierdie 'praktyk' word verkry deur meer (en beter) opleidingsdata te ontleed en te interpreteer.
Wat is data-aantekening?
Data-annotasie is die proses om data toe te skryf, te merk of te etiketteer om masjienleeralgoritmes te help om die inligting wat hulle verwerk, te verstaan en te klassifiseer. Hierdie proses is noodsaaklik vir die opleiding van KI-modelle, wat hulle in staat stel om verskillende datatipes akkuraat te verstaan, soos beelde, oudiolêers, videomateriaal of teks.
Stel jou 'n selfbesturende motor voor wat staatmaak op data van rekenaarvisie, natuurlike taalverwerking (NLP) en sensors om akkurate bestuursbesluite te neem. Om die motor se KI-model te help om te onderskei tussen hindernisse soos ander voertuie, voetgangers, diere of padblokkades, moet die data wat dit ontvang, geëtiketteer of geannoteer word.
By leer onder toesig is data-annotasie veral van kardinale belang, aangesien hoe meer benoemde data aan die model gevoer word, hoe vinniger leer dit om outonoom te funksioneer. Met geannoteerde data kan KI-modelle in verskeie toepassings soos kletsbotte, spraakherkenning en outomatisering ontplooi word, wat lei tot optimale werkverrigting en betroubare uitkomste.
Wat is 'n hulpmiddel vir data -etikettering/annotasie?
 In eenvoudige terme is dit 'n platform of 'n portaal waarmee spesialiste en kundiges datastelle van alle soorte kan aanteken, merk of etiketteer. Dit is 'n brug of 'n medium tussen rou data en die resultate wat u masjienleermodules uiteindelik sou uitbreek.
In eenvoudige terme is dit 'n platform of 'n portaal waarmee spesialiste en kundiges datastelle van alle soorte kan aanteken, merk of etiketteer. Dit is 'n brug of 'n medium tussen rou data en die resultate wat u masjienleermodules uiteindelik sou uitbreek.
'N Gegevensetiketteringshulpmiddel is 'n on-prem of wolkgebaseerde oplossing wat opleidingsdata van hoë gehalte vir masjienleermodelle aanteken. Alhoewel baie ondernemings op 'n eksterne verkoper staatmaak om ingewikkelde aantekeninge te doen, het sommige organisasies steeds hul eie gereedskap wat op maat gemaak is of gebaseer is op freeware- of open source-gereedskap wat in die mark beskikbaar is. Sulke instrumente is gewoonlik ontwerp om spesifieke datatipes, byvoorbeeld beeld, video, teks, klank, ens te hanteer. Hulle kan net die opsie kies en hul spesifieke take uitvoer.
Beeldaantekening

Vanuit die datastelle waarop hulle opgelei is, kan u u oë onmiddellik en presies onderskei van u neus en u wenkbrou van u wimpers. Daarom pas die filters wat u toepas perfek, ongeag die vorm van u gesig, hoe naby u aan u kamera is, en meer.
Dus, soos u nou weet, prentnotasie is noodsaaklik in modules wat gesigsherkenning, rekenaarvisie, robotiese visie en meer behels. As AI -kundiges sulke modelle oplei, voeg hulle onderskrifte, identifiseerders en sleutelwoorde by as eienskappe van hul beelde. Die algoritmes identifiseer en verstaan dan uit hierdie parameters en leer outonoom.
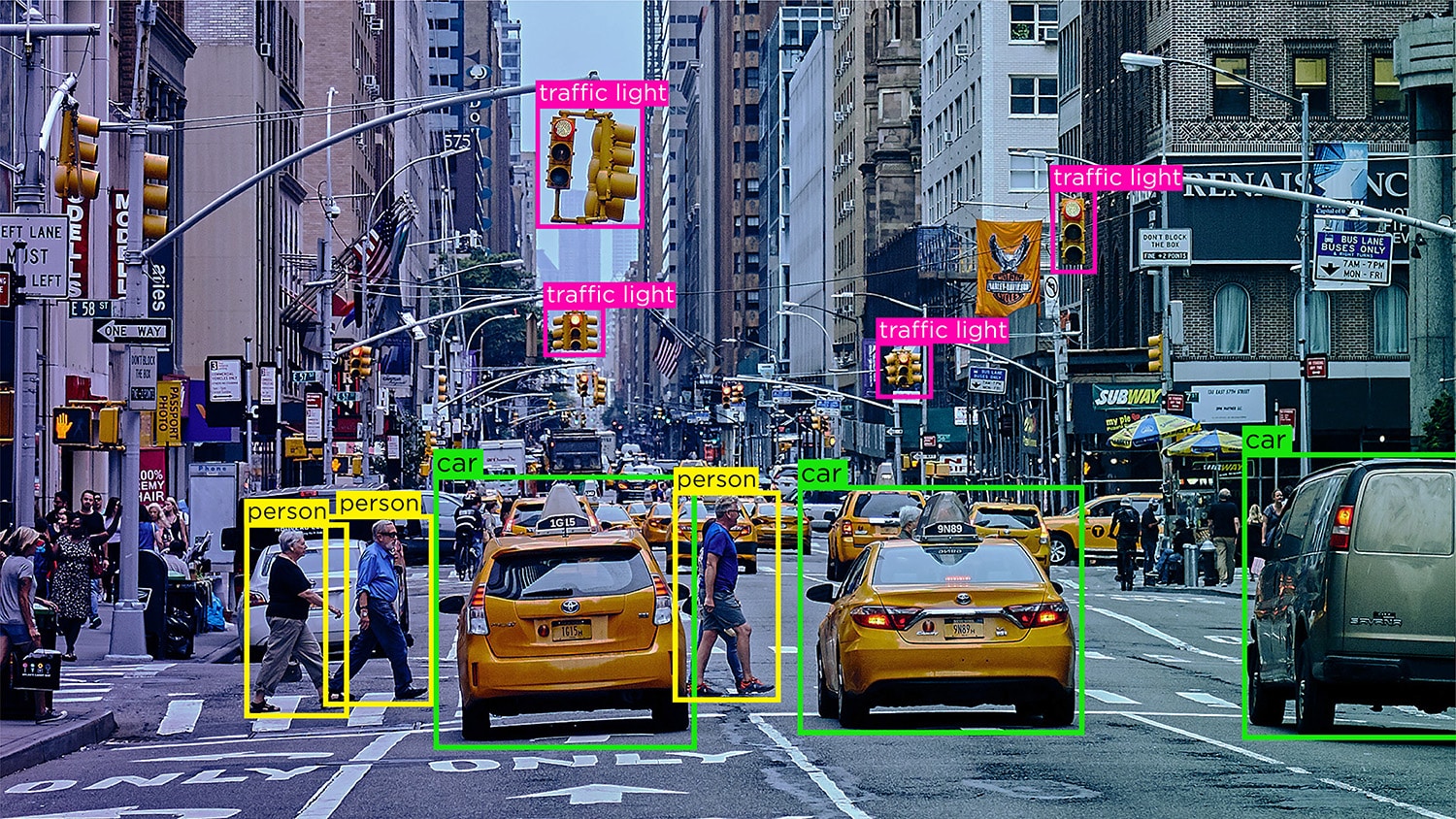
Beeldklassifikasie – Beeldklassifikasie behels die toewysing van voorafbepaalde kategorieë of etikette aan beelde op grond van hul inhoud. Hierdie tipe annotasie word gebruik om KI-modelle op te lei om beelde outomaties te herken en te kategoriseer.
Voorwerpherkenning/Opsporing – Voorwerpherkenning, of objekbespeuring, is die proses om spesifieke voorwerpe binne 'n beeld te identifiseer en byskrifte te maak. Hierdie tipe annotasie word gebruik om KI-modelle op te lei om voorwerpe in werklike beelde of video's op te spoor en te herken.
segmentering – Beeldsegmentering behels die verdeling van 'n beeld in veelvuldige segmente of streke, wat elk ooreenstem met 'n spesifieke voorwerp of area van belang. Hierdie tipe annotasie word gebruik om KI-modelle op te lei om beelde op 'n pixelvlak te analiseer, wat meer akkurate voorwerpherkenning en toneelbegrip moontlik maak.
Klankaantekening
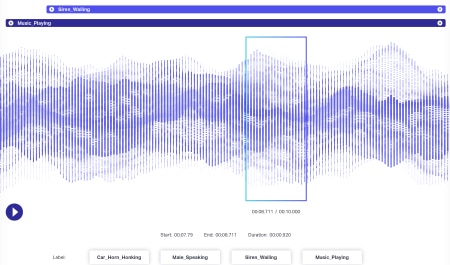
Klankdata bevat selfs meer dinamika as beelddata. Verskeie faktore hou verband met 'n klanklêer, insluitend - maar beslis nie beperk nie - taal, demografie van sprekers, dialekte, stemming, bedoeling, emosie, gedrag. Om algoritmes doeltreffend te verwerk, moet al hierdie parameters geïdentifiseer en gemerk word deur tegnieke soos tydstempel, klankmerke en meer. Behalwe slegs mondelinge aanwysings, kan nie-verbale gevalle soos stilte, asemhaling, selfs agtergrondgeraas vir stelsels 'n volledige begrip kry.
Video-aantekening

Terwyl 'n beeld stil is, is 'n video 'n samestelling van beelde wat 'n effek skep van voorwerpe wat in beweging is. Nou word elke afbeelding in hierdie samestelling 'n raam genoem. Wat video-aantekening betref, behels die proses die toevoeging van sleutelpunte, veelhoeke of omlystings om verskillende voorwerpe in die veld in elke raam aan te teken.
Wanneer hierdie rame saamgestik word, kan die beweging, gedrag, patrone en meer deur die KI-modelle in aksie aangeleer word. Dit is net deur video-aantekening dat konsepte soos lokalisering, bewegingsvervaging en objeknasporing in stelsels geïmplementeer kan word.
Teksaantekening

Vandag is die meeste besighede afhanklik van teksgebaseerde data vir unieke insig en inligting. Nou kan teks enigiets wees wat wissel van klante se terugvoer oor 'n app tot 'n vermelding op sosiale media. En in teenstelling met beelde en video's wat meestal voornemens oordra wat reguit is, kom teks met baie semantiek.
As mens is ons ingestel op die begrip van die konteks van 'n frase, die betekenis van elke woord, sin of frase, dit in verband te bring met 'n sekere situasie of gesprek en besef dan die holistiese betekenis agter 'n stelling. Masjiene, daarenteen, kan dit nie op presiese vlakke doen nie. Konsepte soos sarkasme, humor en ander abstrakte elemente is vir hulle onbekend, en daarom word teksgegewens moeiliker. Daarom het teksaantekeninge meer verfynde stadiums soos die volgende:
Semantiese aantekening - voorwerpe, produkte en dienste word meer relevant gemaak deur toepaslike sleutelwoorde en identifikasieparameters. Chatbots word ook gemaak om menslike gesprekke op hierdie manier na te boots.
Voorneme-aantekening - die bedoeling van 'n gebruiker en die taal wat hulle gebruik, is gemerk vir masjiene om te verstaan. Hiermee kan modelle 'n versoek onderskei van 'n opdrag, of aanbeveling van 'n bespreking, ensovoorts.
Sentimentaantekening – Sentimentaantekening behels die etikettering van tekstuele data met die sentiment wat dit oordra, soos positief, negatief of neutraal. Hierdie tipe annotasie word algemeen gebruik in sentimentanalise, waar KI-modelle opgelei word om die emosies wat in teks uitgedruk word, te verstaan en te evalueer.

Entiteitaantekening - waar ongestruktureerde sinne gemerk word om dit sinvoller te maak en na 'n formaat te bring wat deur masjiene verstaan kan word. Om dit te laat geskied, is twee aspekte betrokke: benoemde entiteitsherkenning en entiteitskakeling. Genoemde entiteitherkenning is wanneer name van plekke, mense, gebeure, organisasies en meer gemerk en geïdentifiseer word en entiteitskakeling is wanneer hierdie etikette gekoppel word aan sinne, frases, feite of opinies wat daarop volg. Gesamentlik vestig hierdie twee prosesse die verband tussen die geassosieerde tekste en die stelling rondom dit.
Teks Kategorisering – Sinne of paragrawe kan gemerk en geklassifiseer word op grond van oorkoepelende onderwerpe, neigings, onderwerpe, menings, kategorieë (sport, vermaak en soortgelyke) en ander parameters.
Sleutelstappe in data-etikettering en data-annotasieproses
Die data-aantekeningproses behels 'n reeks goed gedefinieerde stappe om hoëgehalte en akkurate data-etikettering vir masjienleertoepassings te verseker. Hierdie stappe dek elke aspek van die proses, van data-insameling tot die uitvoer van die geannoteerde data vir verdere gebruik.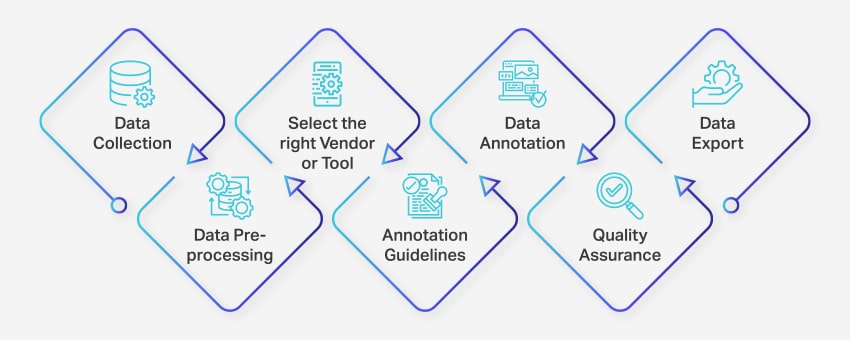
Dit is hoe data-annotasie plaasvind:
- Data-insameling: Die eerste stap in die data-aantekeningproses is om al die relevante data, soos beelde, video's, oudio-opnames of teksdata, op 'n gesentraliseerde plek te versamel.
- Datavoorverwerking: Standaardiseer en verbeter die versamelde data deur prente te skeeftrek, teks te formateer of video-inhoud te transkribeer. Voorverwerking verseker dat die data gereed is vir annotasie.
- Kies die regte verskaffer of gereedskap: Kies 'n toepaslike data-aantekeninginstrument of -verskaffer gebaseer op jou projek se vereistes. Opsies sluit in platforms soos Nanonette vir data-annotasie, V7 vir beeldannotasie, Appen vir video-annotasie en Nanonette vir dokumentannotasie.
- Aantekeningriglyne: Vestig duidelike riglyne vir annoteerders of annotasie-nutsmiddels om konsekwentheid en akkuraatheid regdeur die proses te verseker.
- body: Benoem en merk die data deur menslike annoteerders of data-aantekeningsagteware te gebruik, volgens die gevestigde riglyne.
- Gehalteversekering (QA): Hersien die geannoteerde data om akkuraatheid en konsekwentheid te verseker. Gebruik verskeie blinde aantekeninge, indien nodig, om die kwaliteit van die resultate te verifieer.
- Data-uitvoer: Nadat u die data-aantekening voltooi het, voer die data in die vereiste formaat uit. Platforms soos Nanonets maak dit moontlik om naatlose data-uitvoer na verskeie besigheidsagtewaretoepassings te maak.
Die hele data-aantekeningproses kan wissel van 'n paar dae tot 'n paar weke, afhangende van die projek se grootte, kompleksiteit en beskikbare hulpbronne.
Funksies vir gereedskap vir data-aantekeninge en data-etikette
Gereedskap vir data -annotasie is deurslaggewende faktore wat u AI -projek kan maak of breek. As dit kom by presiese uitsette en resultate, maak die kwaliteit van datastelle alleen nie saak nie. Trouens, die data -annotasie -instrumente wat u gebruik om u AI -modules op te lei, beïnvloed u uitsette geweldig.
Daarom is dit noodsaaklik om die mees funksionele en toepaslike data -etiketteringsinstrument te kies en te gebruik wat aan u sake- of projekbehoeftes voldoen. Maar wat is in die eerste plek 'n hulpmiddel vir data -annotasie? Watter doel dien dit? Is daar tipes? Wel, laat ons uitvind.
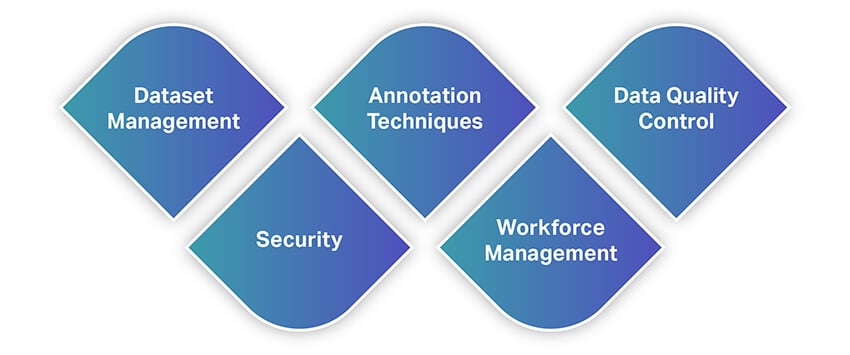
Soortgelyk aan ander gereedskap, bied data -annotasie -instrumente 'n wye verskeidenheid funksies en funksies. Hier is 'n lys van 'n paar van die belangrikste elemente waarna u moet kyk as u 'n data -annotasie -instrument kies om u 'n vinnige idee van funksies te gee.
Datastelbestuur
Die data -annotasiehulpmiddel wat u van plan is om te gebruik, moet die datastelle wat u in die hand het, ondersteun en u in die sagteware vir etikettering kan invoer. Die bestuur van u datastelle is dus die belangrikste funksiehulpmiddels. Hedendaagse oplossings bied funksies waarmee u groot hoeveelhede data naatloos kan invoer, en u tegelykertyd u datastelle kan organiseer deur aksies soos sorteer, filter, kloon, saamsmelt en meer.
Sodra die invoer van u datastelle gedoen is, moet u dit as bruikbare lêers uitvoer. Met die instrument wat u gebruik, kan u u datastelle stoor in die formaat wat u spesifiseer, sodat u dit in u ML -modelle kan invoer.
Annotasietegnieke
Dit is waarvoor 'n data -annotasie -instrument gebou of ontwerp is. 'N Soliede hulpmiddel bied u 'n reeks aantekeningstegnieke vir datastelle van alle soorte. Dit is tensy u 'n pasgemaakte oplossing vir u behoeftes ontwikkel. Met u instrument kan u video of beelde van rekenaarvisie, klank of teks van NLP's en transkripsies en meer aanteken. Om dit verder te verfyn, moet daar opsies wees vir die gebruik van afgrendingsbokse, semantiese segmentering, kuboïede, interpolasie, sentimentanalise, spraakdele, verwysingsoplossing en meer.
Vir die oningewydes is daar ook AI-aangedrewe data-annotasie-instrumente. Dit bevat AI -modules wat outonoom leer uit die werkpatrone van 'n aantekenaar en beelde of teks outomaties aanteken. Sulke
modules kan gebruik word om ongelooflike hulp aan aantekenaars te bied, aantekeninge te optimaliseer en selfs kwaliteitskontroles uit te voer.
Datakwaliteitbeheer
As ons van kwaliteitskontroles praat, word daar verskeie gereedskap vir data -aantekeninge uitgevoer met ingeboude kwaliteitstoetsmodules. Hierdeur kan aantekenaars beter met hul spanlede saamwerk en help om werkstrome te optimaliseer. Met hierdie funksie kan aantekenaars opmerkings of terugvoer intyds merk en opspoor, identiteite opspoor agter mense wat lêers verander, vorige weergawes herstel, kies vir konsensus en meer.
Sekuriteit
Aangesien u met data werk, moet sekuriteit van die hoogste prioriteit wees. U werk moontlik aan vertroulike data, soos inligting oor persoonlike besonderhede of intellektuele eiendom. U instrument moet dus lugdigte beveiliging bied ten opsigte van waar die data gestoor word en hoe dit gedeel word. Dit moet gereedskap bied wat toegang tot spanlede beperk, ongemagtigde aflaai en meer voorkom.
Afgesien hiervan moet daar aan sekuriteitstandaarde en protokolle voldoen word.
Werkmagbestuur
'N Gegewensaantekening -instrument is ook 'n soort projekbestuurplatform, waar take aan spanlede toegewys kan word, samewerkingswerk kan plaasvind, resensies moontlik is en meer. Daarom moet u instrument in u werkstroom en proses pas vir optimale produktiwiteit.
Boonop moet die instrument ook 'n minimale leerkurwe hê, aangesien die proses van data -aantekening op sigself tydrowend is. Dit dien geen doel om te veel tyd te spandeer deur bloot die instrument te leer nie. Dit moet dus intuïtief en naatloos wees vir almal om vinnig aan die gang te kom.
Wat is die voordele van data-annotasie?
Data-aantekening is van kardinale belang om masjienleerstelsels te optimaliseer en verbeterde gebruikerservarings te lewer. Hier is 'n paar sleutelvoordele van data-annotasie:
- Verbeterde opleidingsdoeltreffendheid: Data-etikettering help om masjienleermodelle beter opgelei te word, wat algehele doeltreffendheid verbeter en meer akkurate uitkomste lewer.
- Verhoogde presisie: Akkuraat geannoteerde data verseker dat algoritmes effektief kan aanpas en leer, wat lei tot hoër vlakke van akkuraatheid in toekomstige take.
- Verminderde menslike ingryping: Gevorderde data-aantekeningnutsmiddels verminder die behoefte aan handmatige ingryping aansienlik, vaartbelyning van prosesse en vermindering van gepaardgaande koste.
Data-aantekeninge dra dus by tot meer doeltreffende en presiese masjienleerstelsels, terwyl die koste en handmatige inspanning wat tradisioneel benodig word om KI-modelle op te lei, tot die minimum beperk word.
Om 'n data-aantekening-instrument te bou of nie te bou nie
Een kritieke en oorkoepelende saak wat tydens 'n data-aantekening of data-etiketteringsprojek na vore kan kom, is die keuse om funksies vir hierdie prosesse te bou of te koop. Dit kan verskeie kere in verskillende projekfases opduik, of verband hou met verskillende dele van die program. By die keuse of u 'n stelsel intern wil bou of op verskaffers moet staatmaak, is daar altyd 'n kompromie.

Soos u waarskynlik nou kan sien, is data-aantekening 'n ingewikkelde proses. Terselfdertyd is dit ook 'n subjektiewe proses. Dit beteken dat daar geen enkele antwoord is op die vraag of u 'n instrument vir die aantekening van data moet koop of bou nie. Daar moet baie faktore in ag geneem word en u moet uself 'n paar vrae afvra om u behoeftes te verstaan en te besef of u een moet koop of bou.
Om dit eenvoudig te maak, is hier 'n paar faktore wat u moet oorweeg.
Jou doel
Die eerste element wat u moet definieer, is die doel met u kunsmatige intelligensie en masjienleerbegrippe.
- Waarom implementeer u dit in u besigheid?
- Los hulle 'n werklike probleem op waarmee u kliënte te kampe het?
- Is hulle besig met 'n front-end of backend-proses?
- Sal u AI gebruik om nuwe funksies bekend te stel of u bestaande webwerf, app of 'n module te optimaliseer?
- Wat doen u mededinger in u segment?
- Het u genoeg gebruiksgevalle wat AI-intervensie benodig?
Antwoorde hierop sal u gedagtes - wat tans oral kan voorkom - op een plek saamvat en u meer duidelikheid gee.
AI -data -insameling / -lisensiëring
AI -modelle benodig slegs een element om te funksioneer - data. U moet identifiseer vanwaar u enorme hoeveelhede grondwaarheidsdata kan genereer. As u onderneming groot hoeveelhede data genereer wat verwerk moet word vir belangrike insigte oor sake, bedrywighede, mededingersnavorsing, ontleding van markonbestendigheid, kliëntgedragstudie en meer, benodig u 'n data -annotasiehulpmiddel. U moet egter ook die hoeveelheid data wat u genereer, in ag neem. Soos vroeër genoem, is 'n AI -model net so effektief as die kwaliteit en hoeveelheid data wat dit gevoer word. U besluite moet dus altyd van hierdie faktor afhang.
As u nie die regte data het om u ML-modelle op te lei nie, kan verskaffers baie handig te pas kom en u help met die lisensiëring van data vir die regte stel data wat benodig word om ML-modelle op te lei. In sommige gevalle behels 'n deel van die waarde wat die ondernemer bied, tegniese vaardighede en toegang tot hulpbronne wat die sukses van die projek sal bevorder.
Begroting
Nog 'n fundamentele voorwaarde wat waarskynlik elke faktor beïnvloed wat ons tans bespreek. Die oplossing vir die vraag of u 'n data-aantekening moet bou of koop, word maklik as u verstaan of u genoeg begroting het om te spandeer.
Nakomingskompleksiteite
 Verskaffers kan uiters nuttig wees as dit kom by privaatheid van data en die korrekte hantering van sensitiewe data. Een van hierdie tipe gebruiksgevalle het betrekking op 'n hospitaal of gesondheidsorgverwante onderneming wat die krag van masjienleer wil benut sonder om die nakoming van HIPAA en ander data-privaatheidsreëls in gevaar te stel. Selfs buite die mediese veld verskerp wette soos die Europese AVG die beheer van datastelle en verg meer waaksaamheid van korporatiewe belanghebbendes.
Verskaffers kan uiters nuttig wees as dit kom by privaatheid van data en die korrekte hantering van sensitiewe data. Een van hierdie tipe gebruiksgevalle het betrekking op 'n hospitaal of gesondheidsorgverwante onderneming wat die krag van masjienleer wil benut sonder om die nakoming van HIPAA en ander data-privaatheidsreëls in gevaar te stel. Selfs buite die mediese veld verskerp wette soos die Europese AVG die beheer van datastelle en verg meer waaksaamheid van korporatiewe belanghebbendes.
Manpower
Data -annotasie vereis dat vaardige mannekrag werk, ongeag die grootte, omvang en domein van u onderneming. Selfs as u elke dag minimale data genereer, benodig u data -kundiges om aan u data te werk vir etikettering. Dus, nou moet u besef of u die nodige mannekrag het; as u dit wel het, is hulle vaardig in die nodige gereedskap en tegnieke, of het hulle opleiding nodig? Het u die begroting om hulle in die eerste plek op te lei as hulle opleiding nodig het?
Boonop neem die beste programaantekeninge en data-etiketteringsprogramme 'n aantal vakmense of domeinkenners en segmenteer dit volgens demografie soos ouderdom, geslag en kundigheidsgebied - of dikwels in terme van die plaaslike tale waarmee hulle sal werk. Dit is weer eens waar ons by Shaip praat oor die regte mense op die regte sitplekke en sodoende die regte mens-in-die-loop-prosesse dryf wat u programmatiese pogings tot sukses sal lei.
Klein en groot projekbedrywighede en kostedrempels
In baie gevalle kan ondersteuning van verkopers meer 'n opsie wees vir 'n kleiner projek of vir kleiner projekfases. As die koste beheerbaar is, kan die onderneming baat by uitkontraktering om data -aantekeninge of data -etiketteringsprojekte doeltreffender te maak.
Maatskappye kan ook na belangrike drempels kyk - waar baie verskaffers die koste in verband bring met die hoeveelheid data wat verbruik word of ander hulpbronstandaarde. Kom ons sê byvoorbeeld dat 'n onderneming by 'n verskaffer aangemeld het vir die vervelige data -invoer wat nodig is vir die opstel van toetsstelle.
Daar kan 'n verborge drempel in die ooreenkoms wees, waar die sakevennoot byvoorbeeld nog 'n AWS-datastoor of 'n ander dienskomponent van Amazon Web Services of 'n ander derde-party-verkoper moet verwyder. Dit gee dit aan die klant in die vorm van hoër koste, en dit plaas die prys buite die bereik van die klant.
In hierdie gevalle help die meting van die dienste wat u van verskaffers kry, om die projek bekostigbaar te hou. As u die regte omvang het, sal dit verseker dat die projekkoste nie die redelike of uitvoerbare bedrag vir die betrokke onderneming oorskry nie.
Oopbron- en freeware-alternatiewe
 Sommige alternatiewe vir volledige verskafferondersteuning behels die gebruik van open-source sagteware, of selfs freeware, om projekte vir die aantekening of etikettering van data aan te pak. Hier is 'n soort middelgrond waar maatskappye nie alles van nuuts af skep nie, maar ook nie te veel op kommersiële ondernemers vertrou nie.
Sommige alternatiewe vir volledige verskafferondersteuning behels die gebruik van open-source sagteware, of selfs freeware, om projekte vir die aantekening of etikettering van data aan te pak. Hier is 'n soort middelgrond waar maatskappye nie alles van nuuts af skep nie, maar ook nie te veel op kommersiële ondernemers vertrou nie.
Die doen-dit-self-mentaliteit van open source is op sigself 'n kompromis - ingenieurs en interne mense kan gebruik maak van die open source-gemeenskap, waar gedesentraliseerde gebruikersbasis hul eie voetsoolvlak-ondersteuning bied. Dit sal nie wees soos wat u van 'n ondernemer kry nie - u sal nie 24/7 maklike hulp of antwoorde op vrae kry sonder om interne navorsing te doen nie - maar die prys is laer.
Die groot vraag: wanneer moet u 'n hulpmiddel vir data-aantekening koop:
Soos met baie soorte hoëtegnologiese projekte, benodig hierdie tipe analise - wanneer om te bou en wanneer om te koop - toegewyde nadenke en oorweging oor hoe hierdie projekte verkry en bestuur word. Die uitdagings wat die meeste maatskappye in die gesig staar met betrekking tot AI / ML-projekte as hulle die "bou" -opsie oorweeg, gaan nie net oor die bou- en ontwikkelingsgedeeltes van die projek nie. Daar is dikwels 'n enorme leerkurwe om selfs op die punt te kom waar ware AI / ML-ontwikkeling kan plaasvind. Met nuwe AI / ML-spanne en -inisiatiewe is die aantal "onbekende onbekendes" baie swaarder as die aantal "bekende onbekendes."
| Bou | koop |
|---|---|
Pros:
| Pros:
|
Nadele:
| Nadele:
|
Om dinge nog eenvoudiger te maak, oorweeg die volgende aspekte:
- wanneer u aan groot hoeveelhede data werk
- wanneer u aan verskillende soorte data werk
- wanneer die funksies wat verband hou met u modelle of oplossings in die toekoms kan verander of ontwikkel
- as u 'n vae of generiese gebruiksgeval het
- as u 'n duidelike idee het van die uitgawes verbonde aan die implementering van 'n instrument vir die aantekening van data
- en as u nie die regte personeellede of kundige kundiges het om aan die gereedskap te werk nie en op soek is na 'n minimale leerkurwe
As u antwoorde teenoor hierdie scenario's was, moet u fokus op die bou van u gereedskap.
Hoe om die regte data-aantekeninginstrument vir u projek te kies
As u dit lees, klink hierdie idees opwindend en is dit beslis makliker gesê as gedaan. So, hoe kan 'n mens gebruik maak van die oorvloed gereedskap wat reeds bestaan vir data-aantekeninge? Die volgende stap is dus die oorweging van die faktore wat verband hou met die keuse van die regte instrument vir die aantekening van data.
In teenstelling met 'n paar jaar gelede, het die mark vandag in die praktyk met tonne instrumente vir die aantekening van data ontwikkel. Besighede het meer opsies om een te kies op grond van hul verskillende behoeftes. Maar elke instrument het sy eie voor- en nadele. Om 'n wyse besluit te neem, moet 'n objektiewe roete ook afgesien word van subjektiewe vereistes.
Kom ons kyk na enkele belangrike faktore wat u in die proses moet oorweeg.
Definieer u gebruiksgeval
Om die regte instrument vir die aantekening van data te kies, moet u u gebruiksgeval definieer. U moet besef as u vereiste teks, beeld, video, klank of 'n mengsel van alle datatipes behels. Daar is losstaande hulpmiddels wat u kan koop, en daar is holistiese instrumente wat u toelaat om uiteenlopende aksies op datastelle uit te voer.
Die gereedskap van vandag is intuïtief en bied u opsies in terme van stoorfasiliteite (netwerk, lokaal of wolk), aantekeningstegnieke (klank, beeld, 3D en meer) en 'n aantal ander aspekte. U kan 'n instrument kies op grond van u spesifieke vereistes.
Die daarstelling van gehaltebeheerstandaarde
 Dit is 'n belangrike faktor om in ag te neem, aangesien die doel en doeltreffendheid van u KI-modelle afhang van die kwaliteitstandaarde wat u daarstel. Soos 'n oudit, moet u kwaliteitskontroles doen van die gegewe data en die resultate wat verkry word om te verstaan of u modelle op die regte manier en vir die regte doeleindes opgelei word. Die vraag is egter hoe is u van plan om kwaliteitstandaarde vas te stel?
Dit is 'n belangrike faktor om in ag te neem, aangesien die doel en doeltreffendheid van u KI-modelle afhang van die kwaliteitstandaarde wat u daarstel. Soos 'n oudit, moet u kwaliteitskontroles doen van die gegewe data en die resultate wat verkry word om te verstaan of u modelle op die regte manier en vir die regte doeleindes opgelei word. Die vraag is egter hoe is u van plan om kwaliteitstandaarde vas te stel?
Soos met baie verskillende soorte werk, kan baie mense 'n aantekening en etikettering van data doen, maar hulle doen dit met verskillende mate van sukses. As u 'n diens vra, verifieer u nie outomaties die vlak van gehaltebeheer nie. Daarom wissel die resultate.
Wil u dus 'n konsensusmodel implementeer, waar annoteerders terugvoer bied oor kwaliteit en regstellende maatreëls onmiddellik geneem word? Of verkies u steekproefbeoordeling, goue standaarde of kruising bo vakbondmodelle?
Die beste koopplan sal verseker dat die gehaltebeheer van meet af aan bestaan deur standaarde te stel voordat daar op 'n finale kontrak ooreengekom word. Wanneer u dit vasstel, moet u ook nie foutmarges miskyk nie. Handmatige ingryping kan nie heeltemal vermy word nie, want stelsels kan foute teen 3% verhoog. Dit neem wel werk van voor af, maar dit is die moeite werd.
Wie sal u gegewens aanteken?
Die volgende belangrike faktor is afhanklik van wie u data annoteer. Is u van plan om 'n interne span te hê of wil u dit eerder uitkontrakteer? As u uitkontrakteer, is daar wettigheid en nakomingsmaatreëls wat u moet oorweeg vanweë die probleme rakende privaatheid en vertroulikheid. En as u 'n interne span het, hoe doeltreffend is hulle om 'n nuwe instrument te leer? Wat is u tyd om met u produk of diens te bemark? Het u die regte maatstawwe en spanne om die uitslae goed te keur?
The Vendor vs. Vennootdebat
 Data-aantekening is 'n samewerkingsproses. Dit behels afhanklikhede en ingewikkeldhede soos interoperabiliteit. Dit beteken dat sekere spanne altyd saam met mekaar werk en dat een van die spanne u verkoper kan wees. Daarom is die verkoper of vennoot wat u kies net so belangrik soos die instrument wat u gebruik vir die etikettering van data.
Data-aantekening is 'n samewerkingsproses. Dit behels afhanklikhede en ingewikkeldhede soos interoperabiliteit. Dit beteken dat sekere spanne altyd saam met mekaar werk en dat een van die spanne u verkoper kan wees. Daarom is die verkoper of vennoot wat u kies net so belangrik soos die instrument wat u gebruik vir die etikettering van data.
Met hierdie faktor moet aspekte soos die vermoë om u data en bedoelings vertroulik te hou, die voorneme om terugvoering te aanvaar en daaraan te werk, proaktief te wees in terme van data-rekwisisies, buigsaamheid in bedrywighede en meer, oorweeg word voordat u die hand met 'n verkoper of 'n vennoot skud. . Ons het buigsaamheid ingesluit omdat die vereistes vir data-aantekeninge nie altyd lineêr of staties is nie. Dit kan in die toekoms verander as u u besigheid verder vergroot. As u tans slegs met teksgebaseerde data te make het, wil u klank- of videodata aanteken terwyl u skaal, en u ondersteuning moet gereed wees om hul horison saam met u uit te brei.
Verkoperbetrokkenheid
Een van die maniere om die betrokkenheid van verkopers te bepaal, is die ondersteuning wat u sal ontvang.
By enige koopplan moet hierdie komponent in ag geneem word. Hoe sal ondersteuning op die grond lyk? Wie sal die belanghebbendes en mense wees wat weerskante van die vergelyking is?
Daar is ook konkrete take wat moet uiteensit wat die verkoper se betrokkenheid is (of gaan wees). Sal die verkoper die onbewerkte data aktief verskaf vir 'n data-aantekening of data-etiketteringsprojek? Wie sal optree as vakdeskundiges, en wie sal hulle as werknemers of onafhanklike kontrakteurs in diens neem?
Gevallestudies
Hier is 'n paar spesifieke gevallestudie -voorbeelde wat aanspreek hoe data -annotasie en data -etikettering werklik werk. By Shaip sorg ons vir die hoogste gehalte en uitstekende resultate in data -aantekeninge en etikettering van data.
Baie van die bostaande bespreking van standaardprestasies vir die aantekening van data en die etikettering van data toon aan hoe ons elke projek benader, en wat ons bied aan die ondernemings en belanghebbendes waarmee ons werk.
Gevallestudiemateriaal wat sal aantoon hoe dit werk:

In 'n kliniese data-lisensiëringsprojek het die Shaip-span meer as 6,000 XNUMX uur klank verwerk, alle beskermde gesondheidsinligting (PHI) verwyder en HIPAA-inhoud wat nagekom is, gelaat vir spraakherkenningsmodelle vir gesondheidsorg om aan te werk.
In hierdie soort gevalle is dit die kriteria en klassifikasie van prestasies wat belangrik is. Die onbewerkte data is in die vorm van klank, en dit is nodig om partye te heridentifiseer. Byvoorbeeld, in die gebruik van NER-analise, is die dubbele doel om die inhoud te de-identifiseer en aan te teken.
Nog 'n gevallestudie behels 'n in-diepte gesprekke KI opleiding data projek wat ons voltooi het met 3,000 14 taalkundiges wat oor 'n tydperk van 27 weke gewerk het. Dit het gelei tot die produksie van opleidingsdata in XNUMX tale, ten einde meertalige digitale assistente te ontwikkel wat in staat is om menslike interaksies in 'n wye verskeidenheid inheemse tale te hanteer.
In hierdie spesifieke gevallestudie was die behoefte om die regte persoon in die regte stoel te kry duidelik. Die groot aantal kundiges en inhoudinvoeroperateurs beteken dat organisasie en prosedurele vaartbelyning nodig is om die projek op 'n bepaalde tydlyn te laat afhandel. Ons span kon die bedryfstandaard met 'n wye marge verbygaan deur die versameling van data en daaropvolgende prosesse te optimaliseer.
Ander soorte gevallestudies behels dinge soos bot-opleiding en teksaantekeninge vir masjienleer. Weereens, in 'n teksformaat, is dit steeds belangrik om geïdentifiseerde partye volgens privaatheidswette te behandel en die onbewerkte data te sorteer om die doelgerigte resultate te kry.
Met ander woorde, in die werk oor verskeie datatipes en -formate, het Shaip dieselfde belangrike sukses getoon deur dieselfde metodes en beginsels toe te pas op sowel rou data as sakelissies vir data-lisensiëring.