







Teksversameling

Klank / spraakversameling
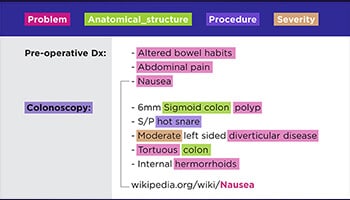
Teksaantekening
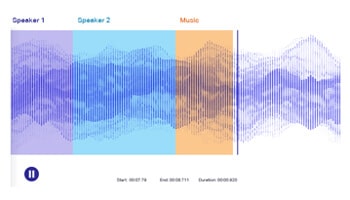
Klank / spraakaantekening

Teks transkripsie

Oudio / spraak transkripsie


Gesprek AI / Chatbot-opleiding
Opleiding vir digitale assistente benodig 'n groot aantal kwaliteitsdata uit verskillende geografiese gebiede, tale, dialekte, opstellings en formate. By Shaip bied ons opleidingsdata aan vir AI-modelle met Human-in-the-loop, wat die nodige kennis, domeinkundigheid het en deeglik bewus is van die spesifieke behoeftes van die kliënt.
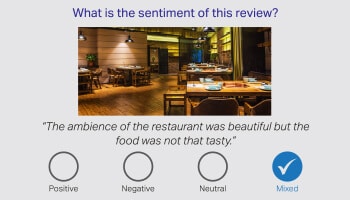
Sentiment / bedoeling
Analise
Daar word tereg gesê dat woorde nie daarin slaag om die hele verhaal te kommunikeer nie, en die plig berus op menslike aantekenaars om die dubbelsinnigheid in die menslike taal te interpreteer. Daarom is die uiters belangrik om die sentiment van 'n klant op grond van die gesprek te identifiseer. Ons taalkenners uit verskillende domeine kan nuanses interpreteer in produkresensies, finansiële nuus en sosiale media.

Benoemde entiteitsherkenning (NER)
Benoemde entiteitsherkenning (NER) is om die benoemde entiteite in 'n teks te identifiseer, te onttrek en te klassifiseer in vooraf gedefinieerde kategorieë. Die teks kan gekategoriseer word as 'n plek, naam, organisasie, produk, hoeveelheid, waarde, persentasie, ens. Met NER kan u vrae in die regte wêreld aanspreek, soos watter organisasies in die artikel genoem is, ens.
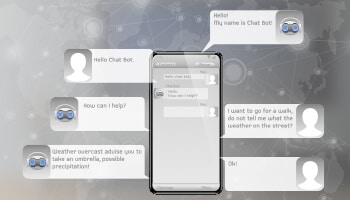
Kliëntediens-outomatisering
Robuuste, goed opgeleide virtuele chatbots of digitale assistente het 'n rewolusie gemaak in die manier waarop klante met die verkopers kommunikeer, wat 'n aansienlike verbetering in die kliënte-ervaring het.

Teks transkripsie
Van dokters se handgeskrewe voorskrifte tot notas vir konferensie-oproepe, ons spesialiste kan enige vorm van data digitaliseer, naamlik argiefdokumente, wettige kontrakte, pasiëntgesondheidsrekords, ens.

Inhoudskategorisering
Kategorisering, ook bekend as klassifikasie of etikettering, is die proses om teks in georganiseerde groepe te klassifiseer en dit te etiketteer, gebaseer op die kenmerke wat dit van belang is.

Onderwerpontleding
Onderwerpanalise of etikettering van onderwerpe is die identifisering en uittreksel van betekenis uit 'n gegewe teks deur herhalende onderwerpe / temas wat oorweeg word, te identifiseer.

Oudio-transkripsie
Transkribeer toespraak / podcast / seminaar, skakel gesprek in teks. Gebruik mense om klank- / spraaklêers akkuraat aan te teken om NLP-modelle akkuraat op te lei.

Klankindeling
Kategoriseer klanke of uitsprake om spraak / klank te klassifiseer op grond van taal, dialek, semantiek, leksikons, ens.

Mense
Toegewyde en opgeleide spanne:
- 30,000+ medewerkers vir die skep van data, etikettering en QA
- Gesertifiseerde projekbestuurspan
- Ervare produkontwikkelingspan
- Talent Pool Sourcing & Onboarding Team

proses
Die hoogste doeltreffendheid van die proses word verseker deur:
- Robuuste 6 Sigma Stage-Gate-proses
- 'N Toegewyde span van 6 Sigma swart gordels - Belangrike prosesseienaars en voldoening aan gehalte
- Deurlopende verbetering en terugvoerlus

platform
Die gepatenteerde platform bied voordele:
- Web-gebaseerde end-to-end platform
- Onberispelike kwaliteit
- Vinniger TAT
- Naadloze aflewering


