
Kunsmatige intelligensie is besig om die musiekbedryf te revolusioneer en bied outomatiese komposisie-, bemeesterings- en uitvoeringsinstrumente. KI-algoritmes genereer nuwe komposisies, voorspel treffers en verpersoonlik luisterervaring, transformeer musiekproduksie, verspreiding en verbruik. Hierdie opkomende tegnologie bied beide opwindende geleenthede en uitdagende etiese dilemmas.
Masjienleer (ML) modelle vereis opleidingsdata om effektief te funksioneer, aangesien 'n komponis musieknote benodig om 'n simfonie te skryf. In die musiekwêreld, waar melodie, ritme en emosie vervleg, kan die belangrikheid van kwaliteit opleidingsdata nie oorbeklemtoon word nie. Dit is die ruggraat van die ontwikkeling van robuuste en akkurate musiek-ML-modelle vir voorspellende analise, genreklassifikasie of outomatiese transkripsie.
Data, die lewensbloed van ML-modelle
Masjienleer is inherent data-gedrewe. Hierdie berekeningsmodelle leer patrone uit die data, wat hulle in staat stel om voorspellings of besluite te maak. Vir musiek ML-modelle kom opleidingsdata dikwels in gedigitaliseerde musieksnitte, lirieke, metadata of 'n kombinasie van hierdie elemente. Hierdie data se kwaliteit, kwantiteit en diversiteit beïnvloed die model se doeltreffendheid aansienlik.

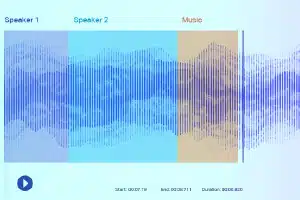
Klanketikettering
Met klanketikettering word die data-annoteerders 'n opname gegee en moet al die nodige klanke skei en benoem. Dit kan byvoorbeeld sekere sleutelwoorde of die klank van 'n spesifieke musiekinstrument wees.

Musiek Klassifikasie
Data-annoteerders kan genres of instrumente in hierdie soort oudio-aantekening merk. Musiekklassifikasie is baie nuttig om musiekbiblioteke te organiseer en gebruikersaanbevelings te verbeter.

Fonetiese vlaksegmentering
Benoem en klassifikasie van fonetiese segmente op die golfvorms en spektrogramme van opnames van individue wat acapella sing.
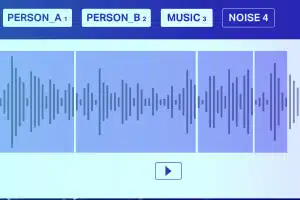
Klankklassifikasie
Behalwe vir stilte/wit geraas, bestaan 'n oudiolêer tipies uit die volgende klanktipes Spraak, Babbel, Musiek en Geraas. Annoteer musieknote akkuraat vir hoër akkuraatheid.
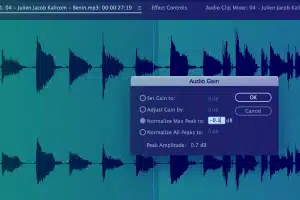
Vaslegging van metadata-inligting
Vang belangrike inligting vas soos begintyd, eindtyd, segment-ID, luidheidsvlak, primêre klanktipe, taalkode, spreker-ID en ander transkripsiekonvensies, ens.


