
Wat is teksannotasie in masjienleer?
Teksannotasie in masjienleer verwys na die byvoeging van metadata of etikette by rou tekstuele data om gestruktureerde datastelle te skep vir opleiding, evaluering en verbetering van masjienleermodelle. Dit is 'n deurslaggewende stap in natuurlike taalverwerking (NLP) take, aangesien dit algoritmes help om te verstaan, te interpreteer en voorspellings te maak gebaseer op teksinsette.
Teksannotasie is belangrik omdat dit help om die gaping tussen ongestruktureerde tekstuele data en gestruktureerde, masjienleesbare data te oorbrug. Dit stel masjienleermodelle in staat om patrone uit die geannoteerde voorbeelde te leer en te veralgemeen.
Aantekeninge van hoë gehalte is noodsaaklik vir die bou van akkurate en robuuste modelle. Dit is hoekom noukeurige aandag aan detail, konsekwentheid en domeinkundigheid noodsaaklik is in teksaantekeninge.
Tipes teksaantekeninge

Wanneer NLP-algoritmes opgelei word, is dit noodsaaklik om groot geannoteerde teksdatastelle te hê wat aangepas is vir elke projek se unieke behoeftes. Dus, vir ontwikkelaars wat sulke datastelle wil skep, hier is 'n eenvoudige oorsig van vyf gewilde teksaantekeningtipes.

Sentiment -aantekening
Sentimentaantekening identifiseer 'n teks se onderliggende emosies, opinies of houdings. Annoteerders benoem tekstuele segmente met positiewe, negatiewe of neutrale sentimentmerkers. Sentimentanalise, 'n sleuteltoepassing van hierdie annotasietipe, word wyd gebruik in sosialemediamonitering, klantterugvoeranalise en marknavorsing.
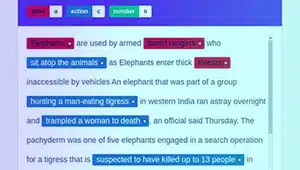
Voorneme-aantekening
Voorneme-annotasie het ten doel om die doel of doel agter 'n gegewe teks vas te lê. In hierdie tipe annotasie ken annoteerders etikette toe aan tekssegmente wat spesifieke gebruikervoornemens verteenwoordig, soos om vir inligting te vra, iets te versoek of 'n voorkeur uit te druk.
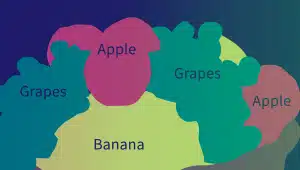
Semantiese aantekening
Semantiese annotasie identifiseer die betekenis en verwantskappe tussen woorde, frases en sinne. Annoteerders gebruik verskeie tegnieke, soos tekssegmentering, dokumentanalise en teksonttrekking, om die semantiese eienskappe van tekselemente te benoem en te klassifiseer.

Entiteitaantekening
Entiteitsaantekeninge is van kardinale belang in die skep van chatbot-opleidingsdatastelle en ander NLP-data. Dit behels die vind en etikettering van entiteite in teks. Tipes entiteitaantekeninge sluit in:

Taalkundige aantekening
Taalkundige annotasie handel oor die strukturele en grammatikale aspekte van taal. Dit sluit verskeie sub-take in, soos woordsoort-etikettering, sintaktiese ontleding en morfologiese analise.

Versekering
Teksaantekeninge help versekeringsmaatskappye om klantterugvoer te ontleed, eise te verwerk en bedrog op te spoor. Deur gebruik te maak van KI-modelle wat op geannoteerde datastelle opgelei is, kan versekeraars:

Bank
Teksaantekeninge fasiliteer verbeterde kliëntediens, bedrogopsporing en dokumentontleding in bankwese. KI-stelsels wat op geannoteerde data opgelei is, kan:

Telecom
Teksaantekeninge stel telekommunikasiemaatskappye in staat om kliëntediens te verbeter, sosiale media te monitor en netwerkkwessies te bestuur. Masjienleermodelle wat op geannoteerde datastelle opgelei is, kan:
Hoe om teksdata te annoteer?
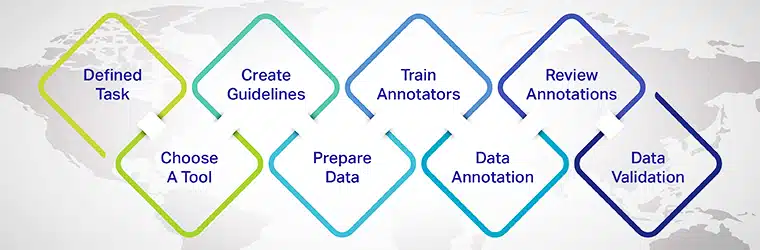
- Definieer die aantekeningtaak: Bepaal die spesifieke NLP-taak wat jy wil aanspreek, soos sentimentanalise, benoemde entiteitsherkenning of teksklassifikasie.
- Kies 'n geskikte annotasie-instrument: Kies 'n teksaantekeninginstrument of -platform wat aan jou projekvereistes voldoen en die verlangde aantekeningtipes ondersteun.
- Skep annotasieriglyne: Ontwikkel duidelike en konsekwente riglyne vir annoteerders om te volg, om hoëgehalte en akkurate aantekeninge te verseker.
- Kies en berei die data voor: Versamel 'n diverse en verteenwoordigende steekproef van rou teksdata vir die annoteerders om aan te werk.
- Lei annoteerders op en evalueer: Verskaf opleiding en deurlopende terugvoer aan annoteerders, wat konsekwentheid en kwaliteit in die annotasieproses verseker.
- Annoteer die data: Annoteerders benoem die teks volgens die gedefinieerde riglyne en annotasietipes.
- Hersien en verfyn aantekeninge: Hersien en verfyn gereeld die aantekeninge, spreek enige inkonsekwenthede of foute aan en verbeter die datastel herhaaldelik.
- Verdeel die datastel: Verdeel die geannoteerde data in opleiding-, validerings- en toetsstelle om die masjienleermodel op te lei en te evalueer.
Wat kan Shaip vir jou doen?
Shaip bied op maat teksaantekening oplossings om jou KI- en masjienleertoepassings in verskeie industrieë aan te dryf. Met 'n sterk fokus op hoë kwaliteit en akkurate aantekeninge, kan Shaip se ervare span en gevorderde aantekeningplatform diverse teksdata hanteer.
Of dit nou sentimentanalise, benoemde entiteitsherkenning of teksklassifikasie is, Shaip lewer pasgemaakte datastelle om te help om jou KI-modelle se taalbegrip en werkverrigting te verbeter.
Vertrou Shaip om jou teksaantekeningproses te stroomlyn en te verseker dat jou KI-stelsels hul volle potensiaal bereik.

